コルーチンとチャネル − チュートリアル
このチュートリアルでは、IntelliJ IDEA でコルーチンを使用して、基盤となるスレッドをブロックしたりコールバックを使用したりせずにネットワークリクエストを実行する方法を学びます。
コルーチンに関する予備知識は必要ありませんが、Kotlin の基本的な構文に慣れていることが前提となります。
このチュートリアルで学べること:
- ネットワークリクエストを実行するために中断関数 (suspending functions) を使用する理由と方法。
- コルーチンを使用してリクエストを並行して送信する方法。
- チャネル (channels) を使用して、異なるコルーチン間で情報を共有する方法。
ネットワークリクエストには Retrofit ライブラリを使用しますが、このチュートリアルで示す手法は、コルーチンをサポートする他のライブラリでも同様に機能します。
すべてのタスクの解答は、プロジェクトのリポジトリの
solutionsブランチで見つけることができます。
始める前に
IntelliJ IDEA の最新バージョンをダウンロードしてインストールします。
ウェルカム画面で Get from VCS を選択するか、File | New | Project from Version Control を選択して、プロジェクトテンプレートをクローンします。
コマンドラインからクローンすることもできます:
Bashgit clone https://github.com/kotlin-hands-on/intro-coroutines
GitHub 開発者トークンを生成する
プロジェクトでは GitHub API を使用します。アクセスするには、GitHub のアカウント名と、パスワードまたはトークンのいずれかを提供する必要があります。2要素認証を有効にしている場合は、トークンだけで十分です。
GitHub の設定から、GitHub API を使用するための新しいトークンを生成してください:
トークンの名前(例:
coroutines-tutorial)を指定します:
スコープは選択しないでください。ページ下部の Generate token をクリックします。
生成されたトークンをコピーします。
コードを実行する
プログラムは、指定された組織(デフォルト名は「kotlin」)の下にあるすべてのリポジトリのコントリビューター(貢献者)を読み込みます。後で、貢献数によってユーザーをソートするロジックを追加します。
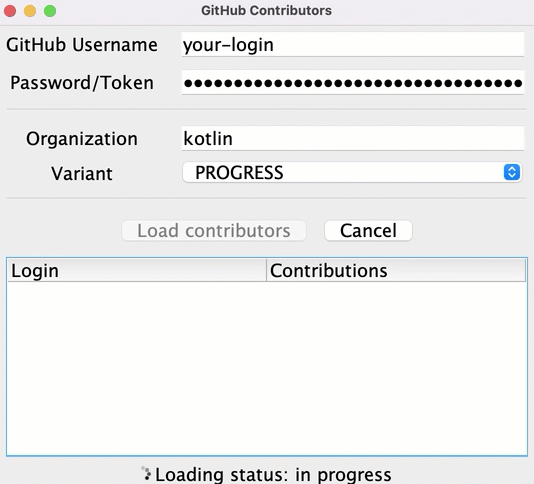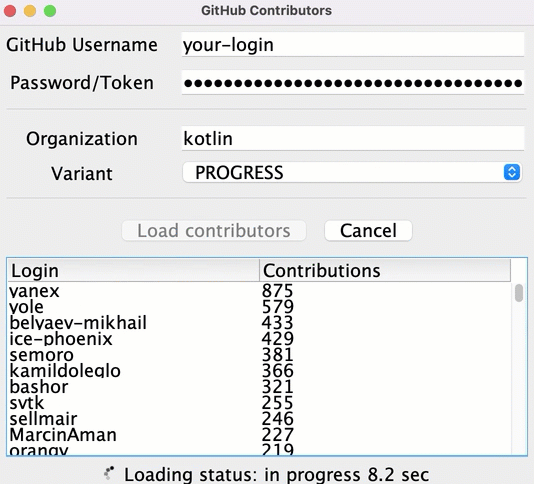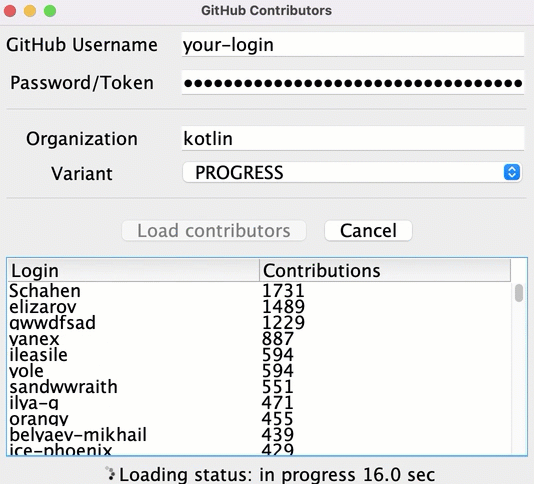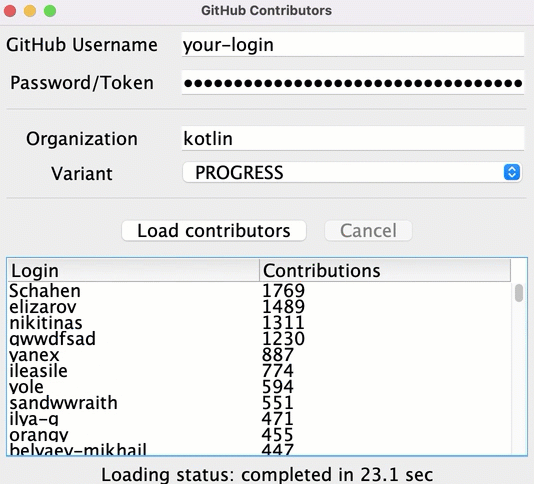
src/contributors/main.ktファイルを開き、main()関数を実行します。以下のウィンドウが表示されます: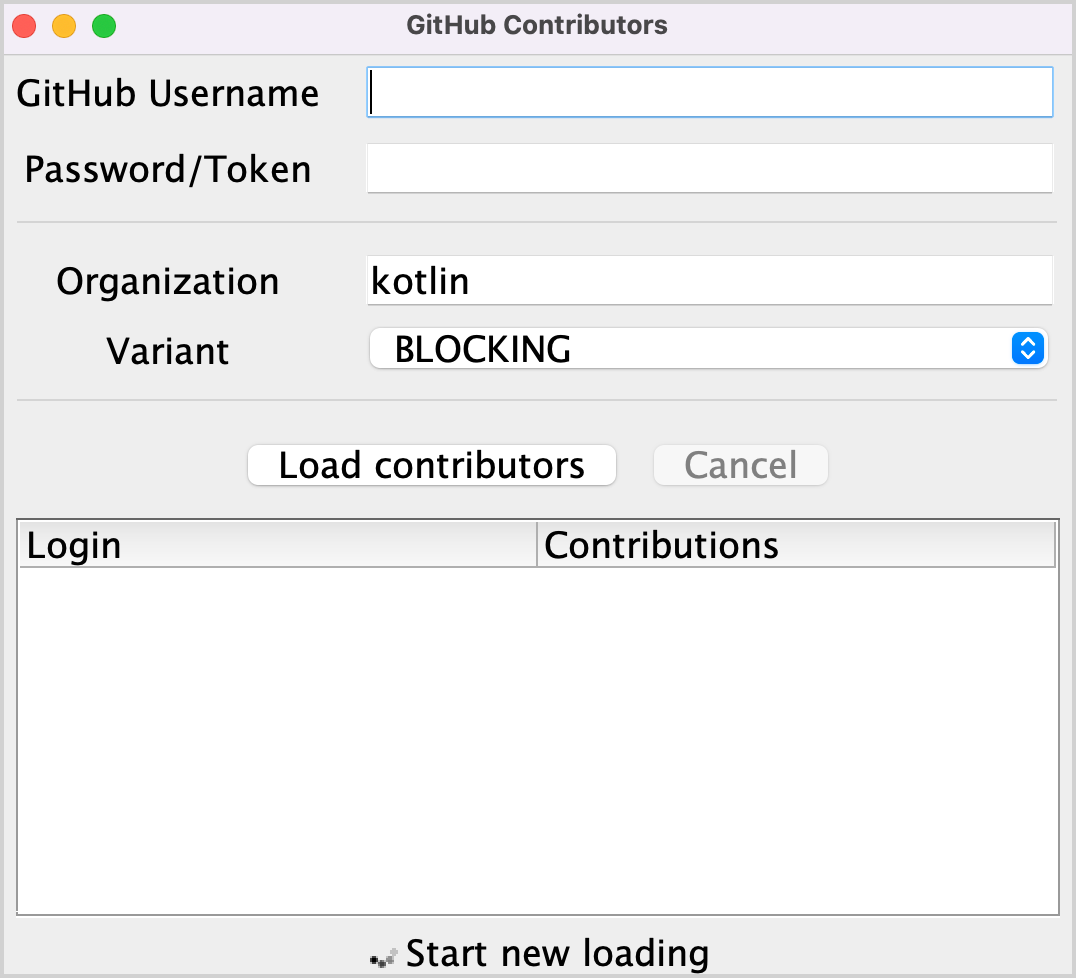
フォントが小さすぎる場合は、
main()関数のsetDefaultFontSize(18f)の値を変更して調整してください。対応するフィールドに GitHub のユーザー名とトークン(またはパスワード)を入力します。
Variant ドロップダウンメニューで BLOCKING オプションが選択されていることを確認します。
Load contributors をクリックします。UI がしばらくフリーズした後、コントリビューターのリストが表示されます。
プログラムの出力を開き、データが読み込まれたことを確認します。リストは各リクエストが成功するたびにログに記録されます。
このロジックを実装するには、ブロッキングリクエストやコールバックを使用するなど、さまざまな方法があります。これらの解決策をコルーチンを使用したものと比較し、チャネルを使用して異なるコルーチン間で情報を共有する方法を確認します。
ブロッキングリクエスト
GitHub への HTTP リクエストを実行するために、Retrofit ライブラリを使用します。これにより、特定の組織下のリポジトリリストと、各リポジトリのコントリビューターリストをリクエストできます。
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
fun getOrgReposCall(
@Path("org") org: String
): Call<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Call<List<User>>
}この API は、特定の組織のコントリビューターリストを取得するために loadContributorsBlocking() 関数によって使用されます。
src/tasks/Request1Blocking.ktを開いて実装を確認してください:kotlinfun loadContributorsBlocking( service: GitHubService, req: RequestData ): List<User> { val repos = service .getOrgReposCall(req.org) // #1 .execute() // #2 .also { logRepos(req, it) } // #3 .body() ?: emptyList() // #4 return repos.flatMap { repo -> service .getRepoContributorsCall(req.org, repo.name) // #1 .execute() // #2 .also { logUsers(repo, it) } // #3 .bodyList() // #4 }.aggregate() }- まず、指定された組織下のリポジトリリストを取得し、それを
reposリストに保存します。次に、各リポジトリについてコントリビューターのリストがリクエストされ、すべてのリストが1つの最終的なコントリビューターリストにマージされます。 getOrgReposCall()とgetRepoContributorsCall()は両方とも*Callクラスのインスタンスを返します (#1)。この時点では、リクエストは送信されていません。- 次に
*Call.execute()が呼び出され、リクエストが実行されます (#2)。execute()は基盤となるスレッドをブロックする同期呼び出しです。 - レスポンスを受け取ると、特定の
logRepos()およびlogUsers()関数を呼び出して結果をログに記録します (#3)。HTTP レスポンスにエラーが含まれている場合、そのエラーはここでログに記録されます。 - 最後に、必要なデータが含まれているレスポンスのボディを取得します。このチュートリアルでは、エラーが発生した場合の結果として空のリストを使用し、対応するエラーをログに記録します (
#4)。
- まず、指定された組織下のリポジトリリストを取得し、それを
.body() ?: emptyList()の繰り返しを避けるために、拡張関数bodyList()が宣言されています:kotlinfun <T> Response<List<T>>.bodyList(): List<T> { return body() ?: emptyList() }プログラムを再度実行し、IntelliJ IDEA のシステム出力を確認してください。以下のようになっているはずです:
text1770 [AWT-EventQueue-0] INFO Contributors - kotlin: loaded 40 repos 2025 [AWT-EventQueue-0] INFO Contributors - kotlin-examples: loaded 23 contributors 2229 [AWT-EventQueue-0] INFO Contributors - kotlin-koans: loaded 45 contributors ...- 各行の最初の項目はプログラム開始からの経過ミリ秒数で、次に角括弧内にスレッド名が表示されます。どのスレッドから読み込みリクエストが呼び出されているかを確認できます。
- 各行の最後の項目は実際のメッセージで、読み込まれたリポジトリまたはコントリビューターの数です。
このログ出力は、すべての結果がメインスレッドからログに記録されたことを示しています。BLOCKING オプションでコードを実行すると、読み込みが終了するまでウィンドウがフリーズし、入力に反応しなくなります。すべてのリクエストは、
loadContributorsBlocking()が呼び出されたスレッドと同じスレッド、つまりメイン UI スレッド(Swing では AWT イベントディスパッチスレッド)から実行されます。このメインスレッドがブロックされるため、UI がフリーズするのです:
コントリビューターのリストが読み込まれた後、結果が更新されます。
src/contributors/Contributors.ktで、コントリビューターの読み込み方法を選択する役割を持つloadContributors()関数を見つけ、loadContributorsBlocking()がどのように呼び出されているかを確認してください:kotlinwhen (getSelectedVariant()) { BLOCKING -> { // UIスレッドをブロックする val users = loadContributorsBlocking(service, req) updateResults(users, startTime) } }updateResults()の呼び出しは、loadContributorsBlocking()呼び出しの直後に行われます。updateResults()は UI を更新するため、常に UI スレッドから呼び出す必要があります。loadContributorsBlocking()も UI スレッドから呼び出されるため、UI スレッドがブロックされ、UI がフリーズします。
タスク 1
最初のタスクは、タスクドメインに慣れるためのものです。現在、各コントリビューターの名前は、参加したプロジェクトごとに1回ずつ、複数回繰り返されています。各コントリビューターが1回だけ追加されるようにユーザーを結合する aggregate() 関数を実装してください。User.contributions プロパティには、そのユーザーのすべてのプロジェクトにおける貢献の合計数を含める必要があります。結果のリストは、貢献数に応じて降順でソートされる必要があります。
src/tasks/Aggregation.kt を開き、List<User>.aggregate() 関数を実装してください。ユーザーは貢献の合計数でソートされる必要があります。
対応するテストファイル test/tasks/AggregationKtTest.kt に、期待される結果の例が示されています。
IntelliJ IDEA のショートカット
Ctrl+Shift+T/⇧ ⌘ Tを使用すると、ソースコードとテストクラスの間を自動的に移動できます。
このタスクを実装した後、「kotlin」組織の結果リストは以下のようになるはずです:
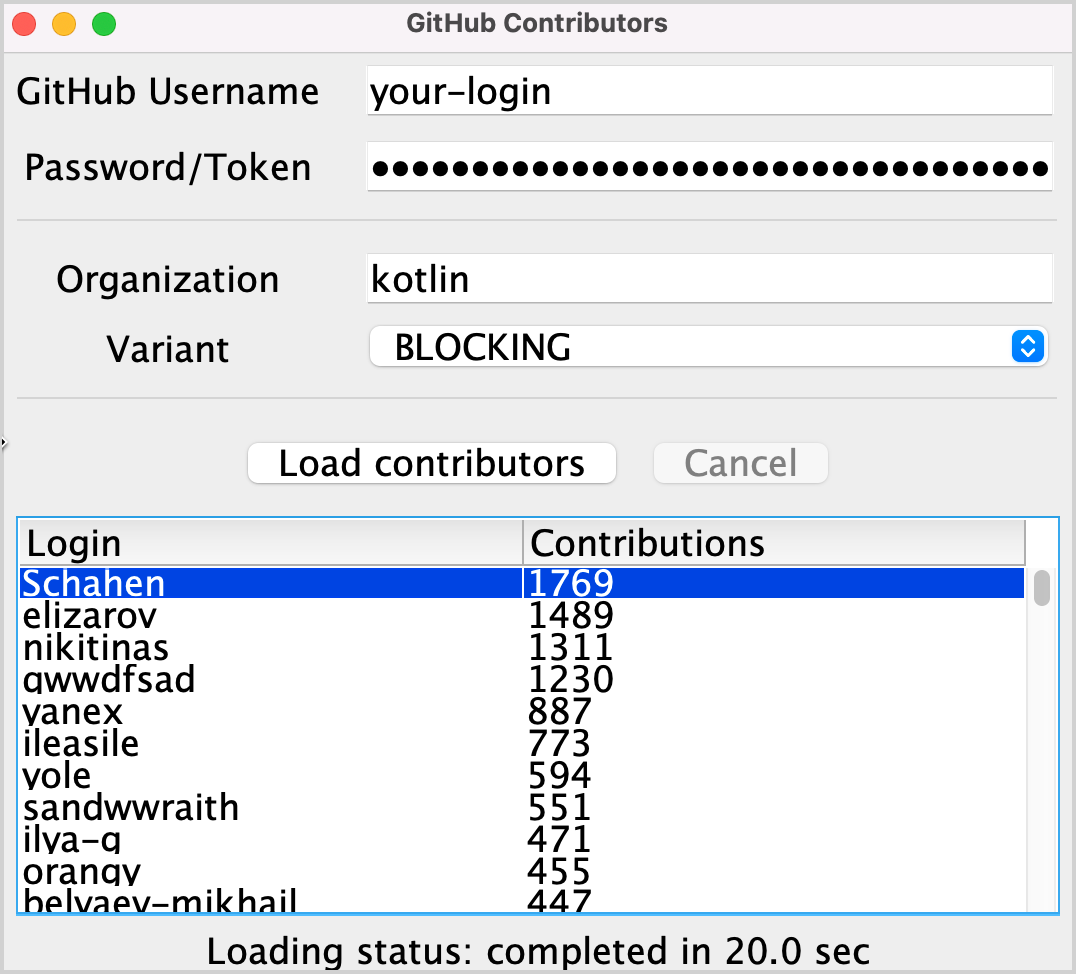
タスク 1 の解決策
ログイン名でユーザーをグループ化するには、
groupBy()を使用します。これにより、ログイン名から、異なるリポジトリにおけるそのログイン名を持つユーザーのすべての出現箇所へのマップが返されます。各マップエントリについて、各ユーザーの貢献の合計数をカウントし、指定された名前と貢献の合計を使用して
Userクラスの新しいインスタンスを作成します。結果のリストを降順でソートします:
kotlinfun List<User>.aggregate(): List<User> = groupBy { it.login } .map { (login, group) -> User(login, group.sumOf { it.contributions }) } .sortedByDescending { it.contributions }
別の解決策として、groupBy() の代わりに groupingBy() 関数を使用することもできます。
コールバック
前の解決策は機能しますが、スレッドをブロックするため UI がフリーズします。これを回避する伝統的なアプローチは、コールバックを使用することです。
操作が完了した直後に呼び出されるべきコードを直接呼び出す代わりに、それを別のコールバック(多くの場合ラムダ)として抽出し、後で呼び出されるように呼び出し元にそのラムダを渡すことができます。
UI のレスポンスを維持するために、計算全体を別のスレッドに移動するか、ブロッキングコールの代わりにコールバックを使用する Retrofit API に切り替えることができます。
バックグラウンドスレッドを使用する
src/tasks/Request2Background.ktを開き、その実装を確認してください。まず、計算全体が別のスレッドに移動されます。thread()関数は新しいスレッドを開始します:kotlinthread { loadContributorsBlocking(service, req) }読み込みがすべて別のスレッドに移動されたため、メインスレッドは解放され、他のタスクに使用できるようになります:

loadContributorsBackground()関数のシグネチャが変更されます。すべての読み込みが完了した後に呼び出すためのupdateResults()コールバックを最後の引数として受け取ります:kotlinfun loadContributorsBackground( service: GitHubService, req: RequestData, updateResults: (List<User>) -> Unit )loadContributorsBackground()が呼び出されると、updateResults()の呼び出しは以前のように直後ではなく、コールバック内で行われます:kotlinloadContributorsBackground(service, req) { users -> SwingUtilities.invokeLater { updateResults(users, startTime) } }SwingUtilities.invokeLaterを呼び出すことで、結果を更新するupdateResults()の呼び出しがメイン UI スレッド(AWT イベントディスパッチスレッド)で行われるようにします。
ただし、BACKGROUND オプションを介してコントリビューターを読み込もうとすると、リストは更新されますが何も変化しないことがわかります。
タスク 2
src/tasks/Request2Background.kt の loadContributorsBackground() 関数を修正し、結果のリストが UI に表示されるようにしてください。
タスク 2 の解決策
コントリビューターを読み込もうとすると、ログにはコントリビューターが読み込まれたことが示されますが、結果が表示されないことがわかります。これを修正するには、結果のユーザーリストに対して updateResults() を呼び出します:
thread {
updateResults(loadContributorsBlocking(service, req))
}コールバックに渡されたロジックを明示的に呼び出すようにしてください。そうしないと、何も起こりません。
Retrofit コールバック API を使用する
前の解決策では、読み込みロジック全体がバックグラウンドスレッドに移動されましたが、それでもリソースの最適な使用とは言えません。すべての読み込みリクエストは順次実行され、読み込み結果を待つ間スレッドはブロックされますが、その間スレッドは他のタスクに使用できたはずです。具体的には、スレッドは別のリクエストの読み込みを開始して、結果全体をより早く受け取ることができた可能性があります。
そのため、各リポジトリのデータの処理は、読み込みと、得られたレスポンスの処理という2つの部分に分けるべきです。2番目の処理部分は、コールバックとして抽出する必要があります。
そうすれば、前のリポジトリの結果を受け取る(そして対応するコールバックが呼び出される)前に、各リポジトリの読み込みを開始できます。

Retrofit のコールバック API はこれを実現するのに役立ちます。Call.enqueue() 関数は HTTP リクエストを開始し、コールバックを引数として受け取ります。このコールバックでは、各リクエストの後に何を行う必要があるかを指定する必要があります。
src/tasks/Request3Callbacks.kt を開き、この API を使用する loadContributorsCallbacks() の実装を確認してください:
fun loadContributorsCallbacks(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
) {
service.getOrgReposCall(req.org).onResponse { responseRepos -> // #1
logRepos(req, responseRepos)
val repos = responseRepos.bodyList()
val allUsers = mutableListOf<User>()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers -> // #2
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
}
}
}
// TODO: なぜこのコードは動かないのか?どうすれば修正できるか?
updateResults(allUsers.aggregate())
}- 便宜上、このコードフラグメントでは同じファイルで宣言されている
onResponse()拡張関数を使用しています。これはオブジェクト式の代わりにラムダを引数として受け取ります。 - レスポンスを処理するロジックはコールバックに抽出されています。対応するラムダは
#1行と#2行で始まります。
しかし、提供された解決策は機能しません。プログラムを実行し、CALLBACKS オプションを選択してコントリビューターを読み込むと、何も表示されないことがわかります。しかし、Request3CallbacksKtTest のテストは、成功したという結果をすぐに返します。
提供されたコードが期待通りに動作しない理由を考え、修正を試みるか、以下の解決策を確認してください。
タスク 3 (オプション)
src/tasks/Request3Callbacks.kt ファイルのコードを書き換えて、読み込まれたコントリビューターのリストが表示されるようにしてください。
タスク 3 の最初の試行解決策
現在の解決策では、多くのリクエストが並行して開始されるため、総読み込み時間が短縮されます。しかし、結果は読み込まれません。これは、updateResults() コールバックが、allUsers リストにデータが入る前、つまりすべての読み込みリクエストが開始された直後に呼び出されるためです。
次のような変更でこれを修正しようとするかもしれません:
val allUsers = mutableListOf<User>()
for ((index, repo) in repos.withIndex()) { // #1
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (index == repos.lastIndex) { // #2
updateResults(allUsers.aggregate())
}
}
}- まず、インデックス付きでリポジトリのリストを反復処理します (
#1)。 - 次に、各コールバックから、それが最後の反復であるかどうかを確認します (
#2)。 - そして、その通りであれば、結果が更新されます。
しかし、このコードも目的を達成できません。自分で答えを探してみるか、以下の解決策を確認してください。
タスク 3 の2番目の試行解決策
読み込みリクエストは並行して開始されるため、最後のリクエストの結果が最後に返ってくる保証はありません。結果はどのような順序でも返ってくる可能性があります。
したがって、完了の条件として現在のインデックスを lastIndex と比較すると、一部のリポジトリの結果を失うリスクがあります。
最後のリポジトリを処理するリクエストが、以前のいくつかのリクエストよりも早く返ってきた場合(その可能性は高いです)、より時間がかかるリクエストのすべての結果が失われてしまいます。
これを修正する1つの方法は、インデックスを導入し、すべてのリポジトリがすでに処理されたかどうかを確認することです:
val allUsers = Collections.synchronizedList(mutableListOf<User>())
val numberOfProcessed = AtomicInteger()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (numberOfProcessed.incrementAndGet() == repos.size) {
updateResults(allUsers.aggregate())
}
}
}一般に、getRepoContributors() リクエストを処理する異なるコールバックが常に同じスレッドから呼び出されるという保証はないため、このコードでは同期されたバージョンのリストと AtomicInteger() を使用しています。
タスク 3 の3番目の試行解決策
さらに良い解決策は、CountDownLatch クラスを使用することです。これは、リポジトリの数で初期化されたカウンターを格納します。このカウンターは、各リポジトリを処理した後にデクリメントされます。その後、ラッチがゼロにカウントダウンされるまで待機してから結果を更新します:
val countDownLatch = CountDownLatch(repos.size)
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
// リポジトリを処理
countDownLatch.countDown()
}
}
countDownLatch.await()
updateResults(allUsers.aggregate())その後、結果はメインスレッドから更新されます。これは、子スレッドにロジックを委任するよりも直接的です。
これら3つの解決策の試行を検討すると、コールバックを使用して正しいコードを書くことは、特に複数の基盤となるスレッドと同期が発生する場合、簡単ではなくエラーが発生しやすいことがわかります。
追加の練習として、RxJava ライブラリを使用したリアクティブなアプローチで同じロジックを実装することもできます。RxJava を使用するために必要なすべての依存関係と解決策は、別の
rxブランチにあります。このチュートリアルを完了し、適切に比較するために提案された Rx バージョンを実装または確認することも可能です。
中断関数 (Suspending functions)
中断関数を使用して同じロジックを実装できます。Call<List<Repo>> を返す代わりに、次のように API 呼び出しを中断関数として定義します:
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): List<Repo>
}getOrgRepos()はsuspend関数として定義されています。中断関数を使用してリクエストを実行すると、基盤となるスレッドはブロックされません。これがどのように機能するかの詳細は、後のセクションで説明します。getOrgRepos()はCallを返すのではなく、直接結果を返します。結果が失敗した場合は、例外がスローされます。
あるいは、Retrofit では Response でラップされた結果を返すこともできます。この場合、結果のボディが提供され、手動でエラーをチェックすることが可能です。このチュートリアルでは、Response を返すバージョンを使用します。
src/contributors/GitHubService.kt で、GitHubService インターフェースに以下の宣言を追加してください:
interface GitHubService {
// getOrgReposCall と getRepoContributorsCall の宣言
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): Response<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
suspend fun getRepoContributors(
@Path("owner") owner: String,
@Path("repo") repo: String
): Response<List<User>>
}タスク 4
あなたのタスクは、2つの新しい中断関数 getOrgRepos() と getRepoContributors() を利用するように、コントリビューターを読み込む関数のコードを変更することです。新しい loadContributorsSuspend() 関数は、新しい API を使用するために suspend とマークされています。
中断関数はどこでも呼び出せるわけではありません。
loadContributorsBlocking()から中断関数を呼び出すと、"Suspend function 'getOrgRepos' should be called only from a coroutine or another suspend function" というメッセージのエラーが発生します。
src/tasks/Request1Blocking.ktで定義されているloadContributorsBlocking()の実装を、src/tasks/Request4Suspend.ktで定義されているloadContributorsSuspend()にコピーします。Callを返す関数の代わりに、新しい中断関数が使用されるようにコードを修正します。- SUSPEND オプションを選択してプログラムを実行し、GitHub リクエストが実行されている間も UI が引き続きレスポンス可能であることを確認します。
タスク 4 の解決策
.getOrgReposCall(req.org).execute() を .getOrgRepos(req.org) に置き換え、2番目の "contributors" リクエストについても同じ置き換えを繰り返します:
suspend fun loadContributorsSuspend(service: GitHubService, req: RequestData): List<User> {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
return repos.flatMap { repo ->
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}.aggregate()
}loadContributorsSuspend()はsuspend関数として定義する必要があります。- API 関数が直接
Responseを返すようになったため、以前はResponseを返していたexecuteを呼び出す必要はもうありません。この詳細は Retrofit ライブラリ特有のものであることに注意してください。他のライブラリでは API は異なりますが、概念は同じです。
コルーチン
中断関数を使用したコードは、「ブロッキング」バージョンに似ています。ブロッキングバージョンとの大きな違いは、スレッドをブロックする代わりに、コルーチンが中断 (suspend) されることです:
ブロック (block) -> 中断 (suspend)
スレッド (thread) -> コルーチン (coroutine)スレッドでコードを実行するのと同様に、コルーチン上でもコードを実行できるため、コルーチンは「軽量スレッド (lightweight threads)」と呼ばれることがよくあります。以前はブロックしていた(そして回避しなければならなかった)操作は、代わりにコルーチンを中断できるようになりました。
新しいコルーチンを開始する
src/contributors/Contributors.kt で loadContributorsSuspend() がどのように使用されているかを見ると、それが launch の中で呼び出されていることがわかります。launch はラムダを引数として受け取るライブラリ関数です:
launch {
val users = loadContributorsSuspend(req)
updateResults(users, startTime)
}ここで launch は、データの読み込みと結果の表示を担当する新しい計算を開始します。この計算は中断可能です。ネットワークリクエストを実行するときは中断され、基盤となるスレッドを解放します。ネットワークリクエストが結果を返すと、計算が再開されます。
このような中断可能な計算は、コルーチンと呼ばれます。つまり、この場合、launch はデータの読み込みと結果の表示を担当する新しいコルーチンを開始します。
コルーチンはスレッドの上で動作し、中断することができます。コルーチンが中断されると、対応する計算は一時停止され、スレッドから取り除かれ、メモリに保存されます。その間、スレッドは他のタスクに使用できるようになります:
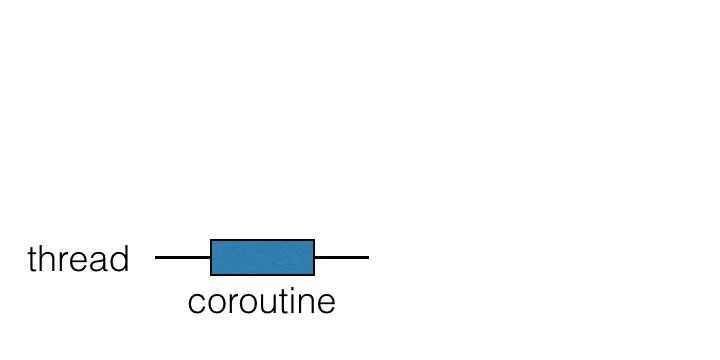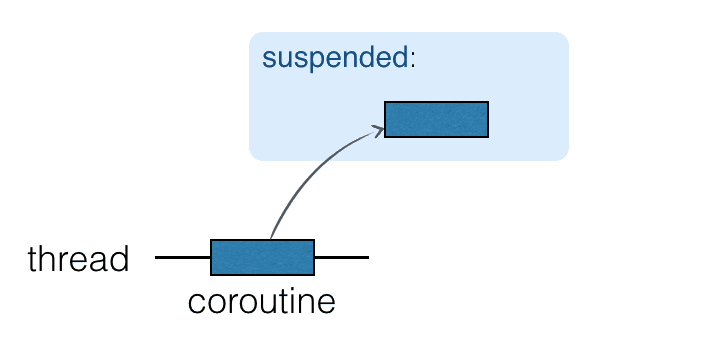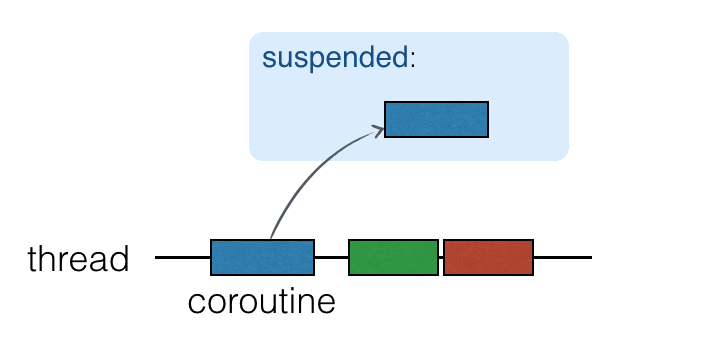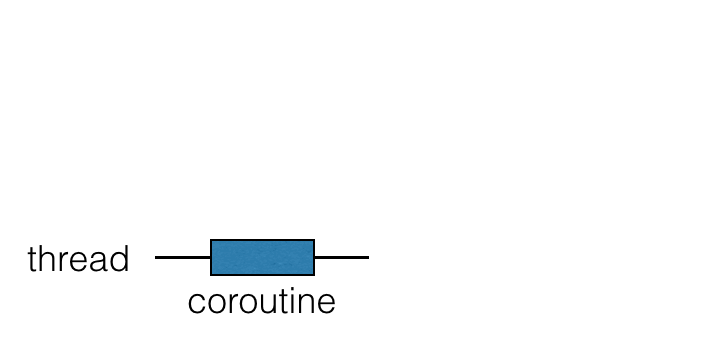
計算を続行する準備が整うと、スレッド(必ずしも同じスレッドとは限りません)に戻されます。
loadContributorsSuspend() の例では、各 "contributors" リクエストが中断メカズムを使用して結果を待ちます。まず、新しいリクエストが送信されます。次に、レスポンスを待つ間、launch 関数によって開始された「コントリビューター読み込み」コルーチン全体が中断されます。
コルーチンは、対応するレスポンスが受信された後にのみ再開されます:
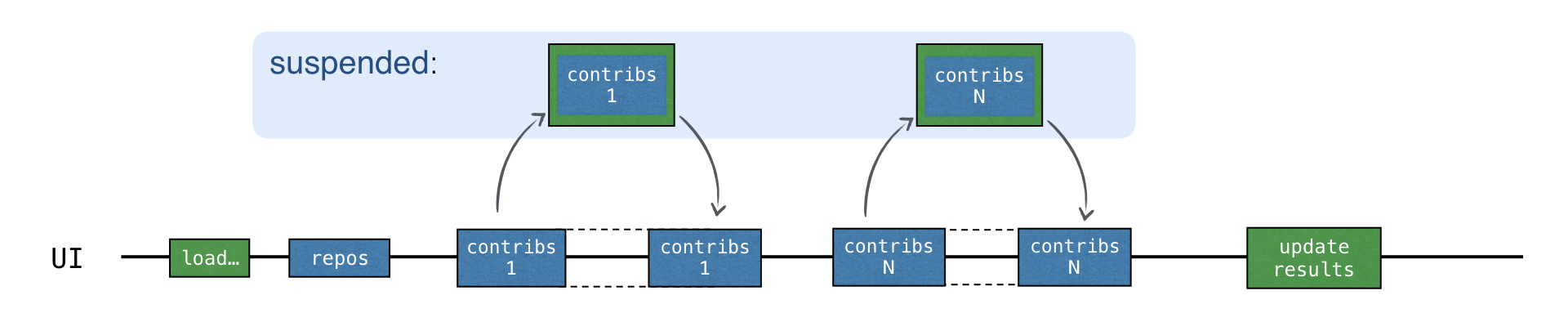
レスポンスが受信されるのを待っている間、スレッドは自由に他のタスクに使用できます。すべてのリクエストがメイン UI スレッドで行われているにもかかわらず、UI のレスポンスは維持されます:
SUSPEND オプションを使用してプログラムを実行します。ログにより、すべてのリクエストがメイン UI スレッドに送信されていることが確認できます:
text2538 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos 2729 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - ts2kt: loaded 11 contributors 3029 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-koans: loaded 45 contributors ... 11252 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-coroutines-workshop: loaded 1 contributorsログには、対応するコードがどのコルーチンで実行されているかを表示できます。これを有効にするには、Run | Edit configurations を開き、
-Dkotlinx.coroutines.debugVM オプションを追加してください: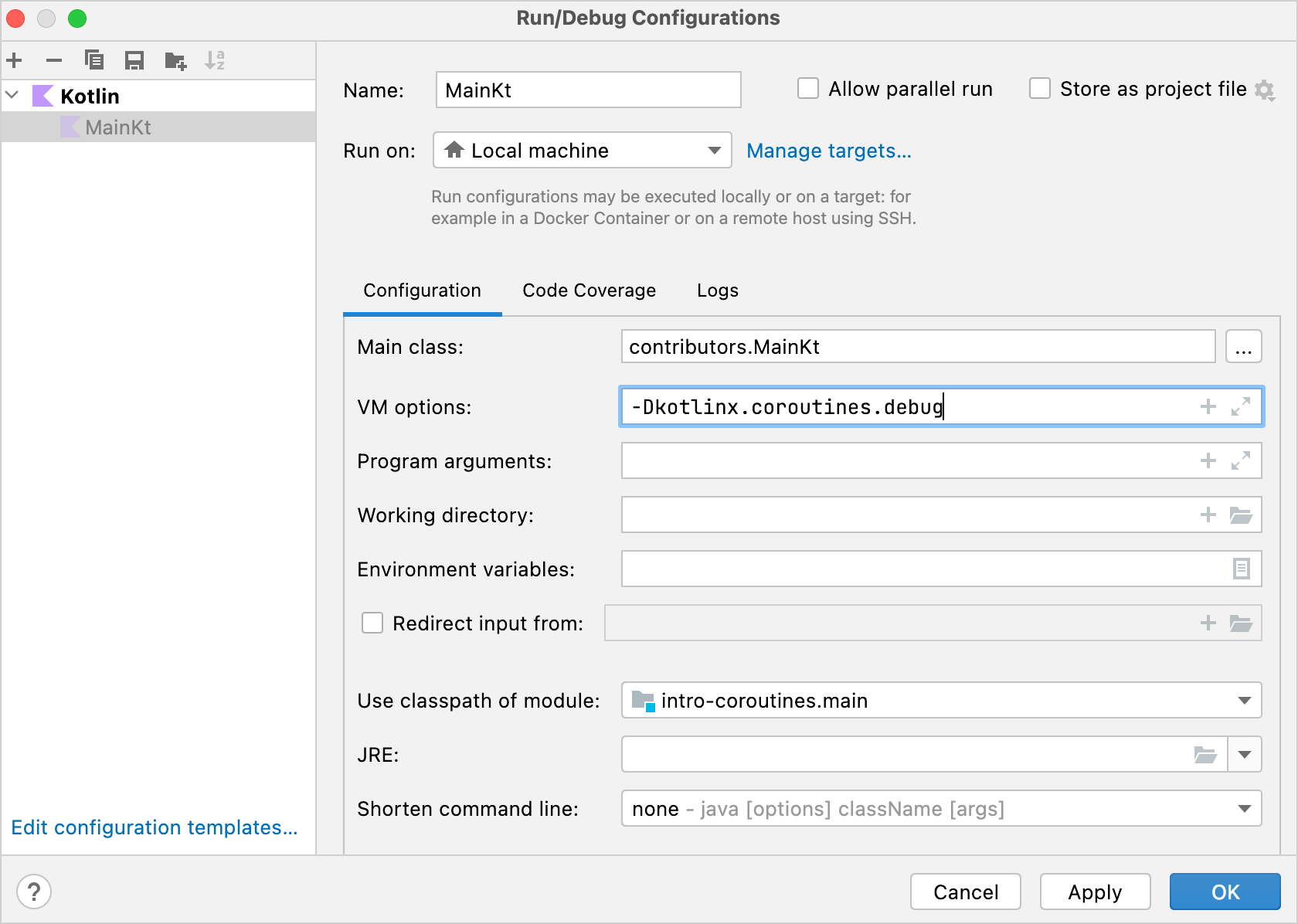
このオプションを付けて
main()を実行すると、スレッド名にコルーチン名が追加されます。また、すべての Kotlin ファイルを実行するためのテンプレートを修正して、デフォルトでこのオプションを有効にすることもできます。
現在、すべてのコードは、上述の @coroutine#1 として示される1つのコルーチン(「コントリビューター読み込み」コルーチン)で実行されています。結果を待っている間、コードは順次書かれているため、他のリクエストを送信するためにスレッドを再利用することはありません。新しいリクエストは、前の結果を受け取ったときにのみ送信されます。
中断関数はスレッドを公平に扱い、「待機」のためにスレッドをブロックしません。ただし、これだけではまだ並行性 (concurrency) は導入されていません。
並行性 (Concurrency)
Kotlin のコルーチンはスレッドよりもはるかにリソース消費が少ないです。新しい計算を非同期的に開始したいときはいつでも、スレッドの代わりに新しいコルーチンを作成できます。
新しいコルーチンを開始するには、主要なコルーチンビルダーのいずれかを使用します:launch、async、または runBlocking です。ライブラリによっては追加のコルーチンビルダーを定義している場合があります。
async は新しいコルーチンを開始し、Deferred オブジェクトを返します。Deferred は、Future や Promise といった他の名前で知られる概念を表します。これは計算を保存しますが、最終的な結果を取得する瞬間を延期 (defer) します。それは、いつか将来 (future) に結果を出すことを約束 (promise) します。
async と launch の主な違いは、launch が特定の値を返すことを期待されていない計算を開始するために使用されることです。launch は、コルーチンを表す Job を返します。Job.join() を呼び出すことで、完了するまで待機することが可能です。
Deferred は Job を拡張するジェネリック型です。async 呼び出しは、ラムダが何を返すかに応じて、Deferred<Int> や Deferred<CustomType> を返すことができます(ラムダ内の最後の式が結果になります)。
コルーチンの結果を取得するには、Deferred インスタンスに対して await() を呼び出すことができます。結果を待っている間、この await() が呼び出されたコルーチンは中断されます:
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferred: Deferred<Int> = async {
loadData()
}
println("waiting...")
println(deferred.await())
}
suspend fun loadData(): Int {
println("loading...")
delay(1000L)
println("loaded!")
return 42
}runBlocking は、通常の関数と中断関数の間、またはブロッキングの世界とノンブロッキングの世界の間の架け橋として使用されます。これは、トップレベルのメインコルーチンを開始するためのアダプターとして機能します。主に main() 関数やテストで使用することを目的としています。
コルーチンをより深く理解するために、このビデオをご覧ください。
Deferred オブジェクトのリストがある場合は、awaitAll() を呼び出してそれらすべての結果を待機できます:
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferreds: List<Deferred<Int>> = (1..3).map {
async {
delay(1000L * it)
println("Loading $it")
it
}
}
val sum = deferreds.awaitAll().sum()
println("$sum")
}各 "contributors" リクエストが新しいコルーチンで開始されると、すべてのリクエストが非同期的に開始されます。前のリクエストの結果を受け取る前に、新しいリクエストを送信できます:
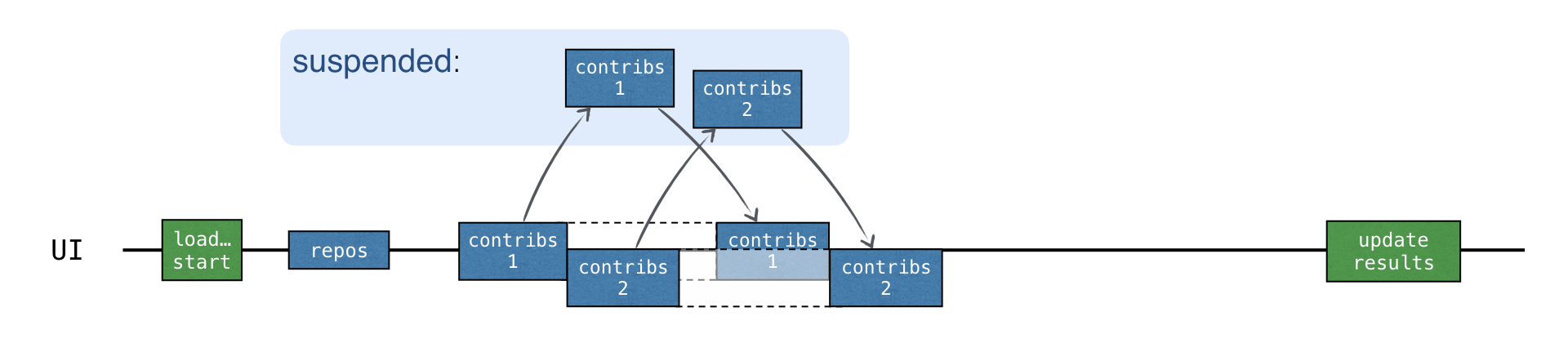
総読み込み時間は CALLBACKS バージョンとほぼ同じですが、コールバックは不要です。さらに、async を使うことで、コード内のどの部分が並行して実行されるかを明確に強調できます。
タスク 5
Request5Concurrent.kt ファイルで、以前の loadContributorsSuspend() 関数を使用して loadContributorsConcurrent() 関数を実装してください。
タスク 5 のヒント
新しいコルーチンはコルーチンスコープ内でのみ開始できます。loadContributorsSuspend() の内容を coroutineScope 呼び出しにコピーして、そこで async 関数を呼び出せるようにしてください:
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
// ...
}以下のスキームに基づいて解決策を作成してください:
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
// 各リポジトリのコントリビューターを読み込む
}
}
deferreds.awaitAll() // List<List<User>>タスク 5 の解決策
各 "contributors" リクエストを async でラップして、リポジトリと同じ数だけコルーチンを作成します。async は Deferred<List<User>> を返します。新しいコルーチンの作成はそれほどリソースを消費しないため、必要なだけ作成しても問題ありません。
mapの結果がリストのリストではなくDeferredオブジェクトのリストになったため、flatMapは使用できなくなりました。awaitAll()はList<List<User>>を返すので、flatten().aggregate()を呼び出して結果を取得します:kotlinsuspend fun loadContributorsConcurrent( service: GitHubService, req: RequestData ): List<User> = coroutineScope { val repos = service .getOrgRepos(req.org) .also { logRepos(req, it) } .bodyList() val deferreds: List<Deferred<List<User>>> = repos.map { repo -> async { service.getRepoContributors(req.org, repo.name) .also { logUsers(repo, it) } .bodyList() } } deferreds.awaitAll().flatten().aggregate() }コードを実行してログを確認します。マルチスレッドがまだ採用されていないため、すべてのコルーチンは依然としてメイン UI スレッドで実行されていますが、コルーチンを並行して実行することの利点はすでに確認できます。
このコードを変更して、共通のスレッドプールから異なるスレッドで "contributors" コルーチンを実行するには、
async関数のコンテキスト引数としてDispatchers.Defaultを指定します:kotlinasync(Dispatchers.Default) { }CoroutineDispatcherは、対応するコルーチンをどのスレッドまたはスレッド群で実行すべきかを決定します。引数として指定しない場合、asyncは外側のスコープのディスパッチャを使用します。Dispatchers.Defaultは JVM 上の共有スレッドプールを表します。このプールは並列実行の手段を提供します。これは利用可能な CPU コアと同じ数のスレッドで構成されますが、コアが1つしかない場合でも2つのスレッドを持ちます。
loadContributorsConcurrent()関数のコードを修正して、共通スレッドプールから異なるスレッドで新しいコルーチンを開始するようにします。また、リクエストを送信する前にログを追加してください:kotlinasync(Dispatchers.Default) { log("starting loading for ${repo.name}") service.getRepoContributors(req.org, repo.name) .also { logUsers(repo, it) } .bodyList() }プログラムをもう一度実行します。ログでは、各コルーチンがスレッドプール内の1つのスレッドで開始され、別のスレッドで再開される可能性があることを確認できます:
text1946 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans 1946 [DefaultDispatcher-worker-3 @coroutine#5] INFO Contributors - starting loading for dokka 1946 [DefaultDispatcher-worker-1 @coroutine#3] INFO Contributors - starting loading for ts2kt ... 2178 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors 2569 [DefaultDispatcher-worker-1 @coroutine#5] INFO Contributors - dokka: loaded 36 contributors 2821 [DefaultDispatcher-worker-2 @coroutine#3] INFO Contributors - ts2kt: loaded 11 contributors例えば、このログの抜粋では、
coroutine#4はworker-2スレッドで開始され、worker-1スレッドで継続されています。
src/contributors/Contributors.kt で、CONCURRENT オプションの実装を確認してください:
メイン UI スレッド上でのみコルーチンを実行するには、引数として
Dispatchers.Mainを指定します:kotlinlaunch(Dispatchers.Main) { updateResults() }- 新しいコルーチンをメインスレッドで開始するときにメインスレッドがビジーな場合、コルーチンは中断され、このスレッドでの実行がスケジュールされます。コルーチンは、スレッドが空いたときにのみ再開されます。
- 各エンドポイントでディスパッチャを明示的に指定するのではなく、外側のスコープのディスパッチャを使用するのが良い習慣とされています。
loadContributorsConcurrent()を定義するときにDispatchers.Defaultを引数として渡さなければ、任意のコンテキスト(Defaultディスパッチャ、メイン UI スレッド、またはカスタムディスパッチャ)でこの関数を呼び出すことができます。 - 後で見るように、テストから
loadContributorsConcurrent()を呼び出す場合、TestDispatcherを持つコンテキストで呼び出すことができ、テストが簡素化されます。これにより、この解決策ははるかに柔軟になります。
呼び出し側でディスパッチャを指定するには、
loadContributorsConcurrentが継承されたコンテキストでコルーチンを開始するようにしたまま、プロジェクトに以下の変更を適用します:kotlinlaunch(Dispatchers.Default) { val users = loadContributorsConcurrent(service, req) withContext(Dispatchers.Main) { updateResults(users, startTime) } }updateResults()はメイン UI スレッドで呼び出す必要があるため、Dispatchers.Mainのコンテキストで呼び出します。withContext()は、指定されたコルーチンコンテキストで指定されたコードを呼び出し、完了するまで中断し、結果を返します。これを表現する、より冗長ですが別の方法は、新しいコルーチンを開始して完了するまで明示的に(中断によって)待機することです:launch(context) { ... }.join()。
コードを実行し、コルーチンがスレッドプールのスレッドで実行されていることを確認します。
構造化された並行性 (Structured concurrency)
- コルーチンスコープは、異なるコルーチン間の構造と親子関係を担当します。新しいコルーチンは通常、スコープ内で開始する必要があります。
- コルーチンコンテキストは、特定のコルーチンを実行するために使用される追加の技術情報(コルーチンのカスタム名や、コルーチンをスケジュールするスレッドを指定するディスパッチャなど)を保存します。
launch、async、または runBlocking を使用して新しいコルーチンを開始すると、対応するスコープが自動的に作成されます。これらの関数はすべてレシーバー付きラムダを引数として受け取り、その暗黙的なレシーバータイプは CoroutineScope です:
launch { /* this: CoroutineScope */ }- 新しいコルーチンはスコープ内でのみ開始できます。
launchとasyncはCoroutineScopeの拡張として宣言されているため、呼び出すときは常に暗黙的または明示的なレシーバーを渡す必要があります。runBlockingで開始されるコルーチンだけが例外です。なぜならrunBlockingはトップレベル関数として定義されているからです。しかし、これは現在のスレッドをブロックするため、主にmain()関数やテストでブリッジ関数として使用されることを目的としています。
runBlocking、launch、または async 内の新しいコルーチンは、スコープ内で自動的に開始されます:
import kotlinx.coroutines.*
fun main() = runBlocking { /* this: CoroutineScope */
launch { /* ... */ }
// 次と同じ:
this.launch { /* ... */ }
}runBlocking 内で launch を呼び出すと、それは CoroutineScope 型の暗黙的なレシーバーの拡張として呼び出されます。あるいは、明示的に this.launch と書くこともできます。
ネストされたコルーチン(この例では launch で開始されたもの)は、外側のコルーチン(runBlocking で開始されたもの)の子と見なすことができます。この「親子」関係はスコープを通じて機能します。子コルーチンは、親コルーチンに対応するスコープから開始されます。
coroutineScope 関数を使用することで、新しいコルーチンを開始せずに新しいスコープを作成することが可能です。外側のスコープにアクセスせずに suspend 関数内で構造化された方法で新しいコルーチンを開始するには、その suspend 関数が呼び出された外側のスコープの子となる新しいコルーチンスコープを自動的に作成できます。loadContributorsConcurrent() は良い例です。
また、GlobalScope.async や GlobalScope.launch を使用して、グローバルスコープから新しいコルーチンを開始することもできます。これにより、トップレベルの「独立した」コルーチンが作成されます。
コルーチンの構造の背後にあるメカニズムは、構造化された並行性 (structured concurrency) と呼ばれます。これはグローバルスコープに対して以下の利点を提供します:
- スコープは通常、子コルーチンに対して責任を持ちます。子コルーチンの寿命はスコープの寿命に紐付けられます。
- 何か問題が発生した場合や、ユーザーが気が変わって操作を取り消すことにした場合、スコープは自動的に子コルーチンをキャンセルできます。
- スコープはすべての子コルーチンの完了を自動的に待ちます。 したがって、スコープがコルーチンに対応している場合、そのスコープで起動されたすべてのコルーチンが完了するまで、親コルーチンは完了しません。
GlobalScope.async を使用する場合、複数のコルーチンをより小さなスコープにバインドする構造はありません。グローバルスコープから開始されたコルーチンはすべて独立しており、その寿命はアプリケーション全体の寿命によってのみ制限されます。グローバルスコープから開始されたコルーチンへの参照を保存して、その完了を待ったり、明示的にキャンセルしたりすることは可能ですが、構造化された並行性のように自動的には行われません。
コントリビューターの読み込みをキャンセルする
コントリビューターのリストを読み込む関数の2つのバージョンを作成します。親コルーチンをキャンセルしようとしたときに、両方のバージョンがどのように動作するかを比較します。最初のバージョンは coroutineScope を使用してすべての子コルーチンを開始し、2番目のバージョンは GlobalScope を使用します。
Request5Concurrent.ktで、loadContributorsConcurrent()関数に3秒の遅延を追加します:kotlinsuspend fun loadContributorsConcurrent( service: GitHubService, req: RequestData ): List<User> = coroutineScope { // ... async { log("starting loading for ${repo.name}") delay(3000) // リポジトリのコントリビューターを読み込む } // ... }遅延はリクエストを送信するすべてのコルーチンに影響するため、コルーチンが開始された後、リクエストが送信される前に読み込みをキャンセルするのに十分な時間があります。
読み込み関数の2番目のバージョンを作成します:
Request5Concurrent.ktのloadContributorsConcurrent()の実装をRequest5NotCancellable.ktのloadContributorsNotCancellable()にコピーし、新しいcoroutineScopeの作成を削除します。async呼び出しが解決できなくなるため、GlobalScope.asyncを使用して開始します:kotlinsuspend fun loadContributorsNotCancellable( service: GitHubService, req: RequestData ): List<User> { // #1 // ... GlobalScope.async { // #2 log("starting loading for ${repo.name}") // リポジトリのコントリビューターを読み込む } // ... return deferreds.awaitAll().flatten().aggregate() // #3 }- 関数はラムダ内の最後の式としてではなく、直接結果を返すようになります(
#1行目と#3行目)。 - すべての "contributors" コルーチンは、コルーチンスコープの子としてではなく、
GlobalScope内で開始されます(#2行目)。
- 関数はラムダ内の最後の式としてではなく、直接結果を返すようになります(
プログラムを実行し、CONCURRENT オプションを選択してコントリビューターを読み込みます。
すべての "contributors" コルーチンが開始されるまで待ち、その後 Cancel をクリックします。ログには新しい結果が表示されません。これは、すべてのリクエストが実際にキャンセルされたことを意味します:
text2896 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 40 repos 2901 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans ... 2909 [DefaultDispatcher-worker-5 @coroutine#36] INFO Contributors - starting loading for mpp-example /* 'cancel' をクリック */ /* リクエストは送信されない */手順5を繰り返しますが、今回は
NOT_CANCELLABLEオプションを選択します:text2570 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos 2579 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - starting loading for kotlin-koans ... 2586 [DefaultDispatcher-worker-6 @coroutine#36] INFO Contributors - starting loading for mpp-example /* 'cancel' をクリック */ /* しかし、すべてのリクエストは依然として送信される: */ 6402 [DefaultDispatcher-worker-5 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors ... 9555 [DefaultDispatcher-worker-8 @coroutine#36] INFO Contributors - mpp-example: loaded 8 contributorsこの場合、コルーチンはキャンセルされず、すべてのリクエストが送信されます。
"contributors" プログラムでキャンセルがどのようにトリガーされるかを確認してください。Cancel ボタンがクリックされると、メインの "loading" コルーチンが明示的にキャンセルされ、子コルーチンは自動的にキャンセルされます:
kotlininterface Contributors { fun loadContributors() { // ... when (getSelectedVariant()) { CONCURRENT -> { launch { val users = loadContributorsConcurrent(service, req) updateResults(users, startTime) }.setUpCancellation() // #1 } } } private fun Job.setUpCancellation() { val loadingJob = this // #2 // 'cancel' ボタンがクリックされた場合に loading ジョブをキャンセルする: val listener = ActionListener { loadingJob.cancel() // #3 updateLoadingStatus(CANCELED) } // 'cancel' ボタンにリスナーを追加する: addCancelListener(listener) // ジョブ完了後にステータスを更新し、リスナーを削除する } }
launch 関数は Job のインスタンスを返します。Job は、すべてのデータを読み込んで結果を更新する「読み込みコルーチン」への参照を保持します。その上で setUpCancellation() 拡張関数を呼び出し (#1 行目)、Job のインスタンスをレシーバーとして渡すことができます。
これを表現する別の方法は、次のように明示的に書くことです:
val job = launch { }
job.setUpCancellation()- 読みやすさのために、関数内の
setUpCancellation()関数のレシーバーを新しいloadingJob変数で参照できます (#2行目)。 - 次に、Cancel ボタンにリスナーを追加して、ボタンがクリックされたときに
loadingJobがキャンセルされるようにします (#3行目)。
構造化された並行性を使用すると、親コルーチンをキャンセルするだけで、これが自動的にすべての子コルーチンにキャンセルを伝播させます。
外側のスコープのコンテキストを使用する
特定のスコープ内で新しいコルーチンを開始すると、それらすべてが同じコンテキストで実行されるようにするのがはるかに簡単になります。また、必要に応じてコンテキストを置き換えるのもはるかに簡単です。
ここで、外側のスコープのディスパッチャを使用する仕組みを学びます。coroutineScope またはコルーチンビルダーによって作成された新しいスコープは、常に外側のスコープからコンテキストを継承します。この場合、外側のスコープは suspend loadContributorsConcurrent() 関数が呼び出されたスコープです:
launch(Dispatchers.Default) { // 外側のスコープ
val users = loadContributorsConcurrent(service, req)
// ...
}すべてのネストされたコルーチンは、継承されたコンテキストで自動的に開始されます。ディスパッチャはこのコンテキストの一部です。そのため、async によって開始されたすべてのコルーチンは、デフォルトディスパッチャのコンテキストで開始されます:
suspend fun loadContributorsConcurrent(
service: GitHubService, req: RequestData
): List<User> = coroutineScope {
// このスコープは外側のスコープからコンテキストを継承する
// ...
async { // ネストされたコルーチンは継承されたコンテキストで開始される
// ...
}
// ...
}構造化された並行性を使用すると、トップレベルのコルーチンを作成するときに主要なコンテキスト要素(ディスパッチャなど)を一度指定するだけで済みます。その後、ネストされたすべてのコルーチンはコンテキストを継承し、必要な場合にのみ変更します。
Android アプリケーションなどの UI アプリケーション用のコルーチンコードを書く場合、トップレベルのコルーチンにデフォルトで
CoroutineDispatchers.Mainを使用し、別のスレッドでコードを実行する必要がある場合に別のディスパッチャを明示的に指定するのが一般的なやり方です。
進捗の表示
一部のリポジトリの情報がかなり早く読み込まれるにもかかわらず、ユーザーはすべてのデータが読み込まれた後にのみ結果リストを見ることになります。それまでは、ローダーアイコンが進捗を表示して回転していますが、現在の状態やどのコントリビューターがすでに読み込まれているかについての情報はありません。
中間結果をより早く表示し、各リポジトリのデータを読み込んだ後にすべてのコントリビューターを表示することができます:
この機能を実装するには、src/tasks/Request6Progress.kt において、UI を更新するロジックをコールバックとして渡す必要があります。これにより、各中間状態で呼び出されるようになります:
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
// データの読み込み
// 中間状態で `updateResults()` を呼び出す
}呼び出し側の Contributors.kt では、PROGRESS オプションのために Main スレッドから結果を更新するようにコールバックが渡されます:
launch(Dispatchers.Default) {
loadContributorsProgress(service, req) { users, completed ->
withContext(Dispatchers.Main) {
updateResults(users, startTime, completed)
}
}
}loadContributorsProgress()では、updateResults()パラメータがsuspendとして宣言されています。対応するラムダ引数内でsuspend関数であるwithContextを呼び出す必要があるためです。updateResults()コールバックは、読み込みが完了し結果が最終的なものであるかどうかを指定する追加の Boolean パラメータを引数として受け取ります。
タスク 6
Request6Progress.kt ファイルで、中間の進捗を表示する loadContributorsProgress() 関数を実装してください。Request4Suspend.kt の loadContributorsSuspend() 関数をベースにしてください。
- 並行性のないシンプルなバージョンを使用してください。並行性は次のセクションで追加します。
- 中間のコントリビューターリストは、各リポジトリについて読み込まれたユーザーリストだけでなく、「集計された (aggregated)」状態で表示される必要があります。
- 新しいリポジトリのデータが読み込まれるたびに、各ユーザーの貢献の合計数が増加するようにしてください。
タスク 6 の解決策
「集計された」状態の中間リストを保存するには、ユーザーリストを保持する allUsers 変数を定義し、各リポジトリのコントリビューターが読み込まれた後にそれを更新します:
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
var allUsers = emptyList<User>()
for ((index, repo) in repos.withIndex()) {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, index == repos.lastIndex)
}
}逐次実行 vs 並行実行
各リクエストが完了するたびに updateResults() コールバックが呼び出されます:
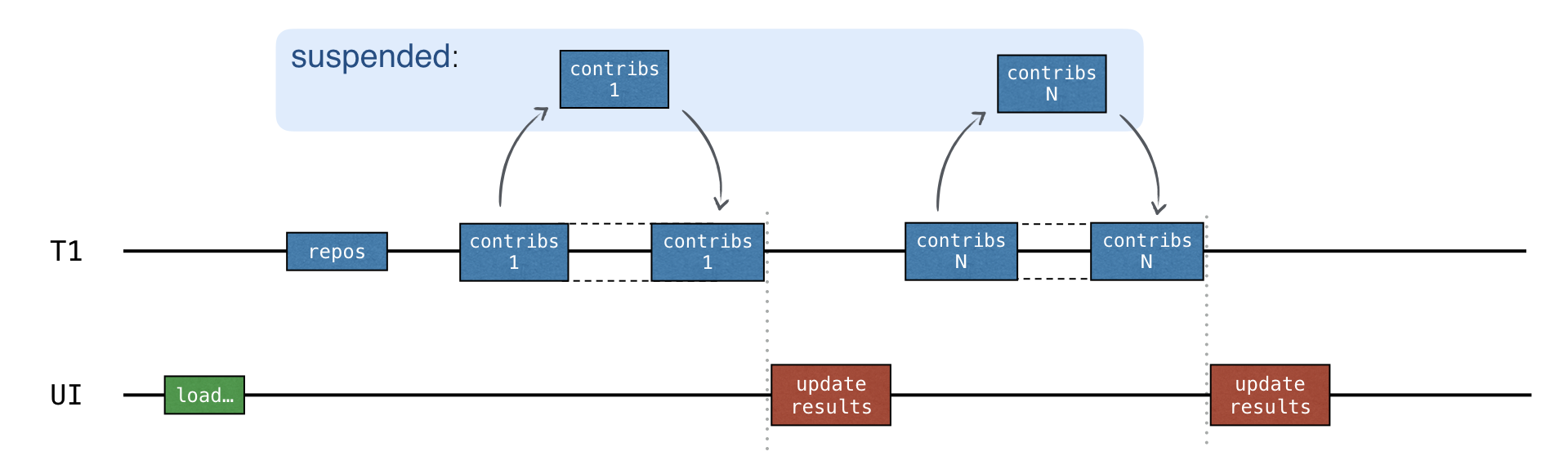
このコードには並行性が含まれていません。逐次的なので、同期は不要です。
最良のオプションは、リクエストを並行して送信し、各リポジトリのレスポンスを受け取った後に中間結果を更新することです:
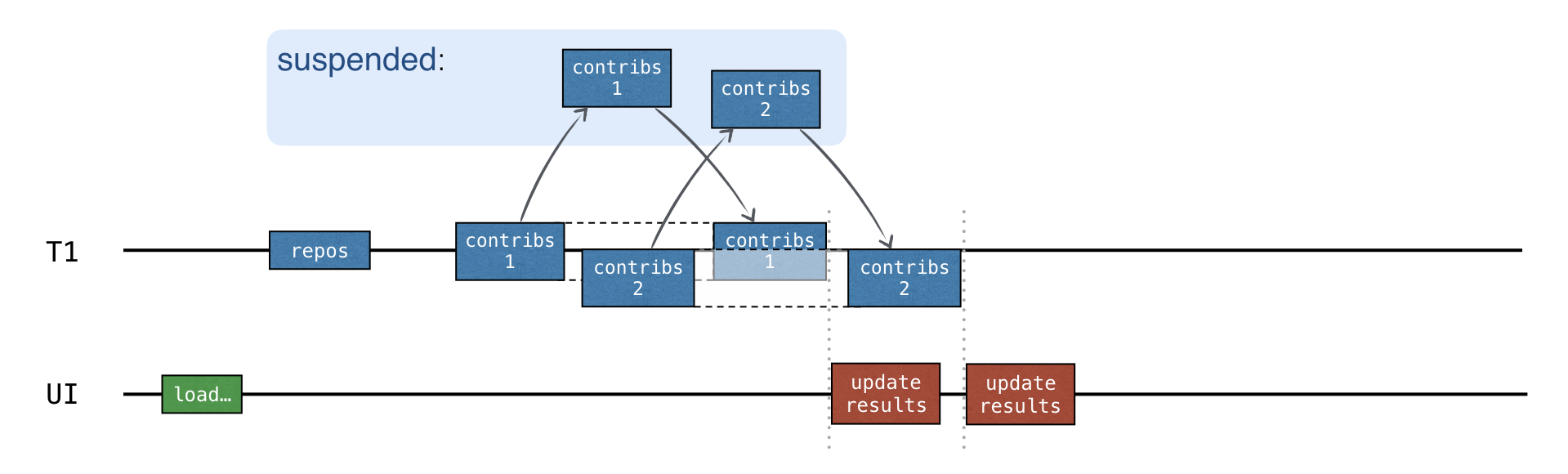
並行性を追加するには、チャネル (channels) を使用します。
チャネル (Channels)
共有された可変状態 (mutable state) を持つコードを書くことは、非常に困難でエラーが発生しやすいです(コールバックを使用した解決策のように)。 よりシンプルな方法は、共通の可変状態を使用するのではなく、通信によって情報を共有することです。 コルーチンは、チャネルを介して互いに通信できます。
チャネルは、コルーチン間でデータを渡すことを可能にする通信プリミティブです。あるコルーチンがチャネルに情報を送信 (send) し、別のコルーチンがそこからその情報を受信 (receive) できます:

情報を送信(生成)するコルーチンはプロデューサー、情報を受信(消費)するコルーチンはコンシューマーと呼ばれることがよくあります。1つまたは複数のコルーチンが同じチャネルに情報を送信でき、1つまたは複数のコルーチンがそこからデータを受信できます:
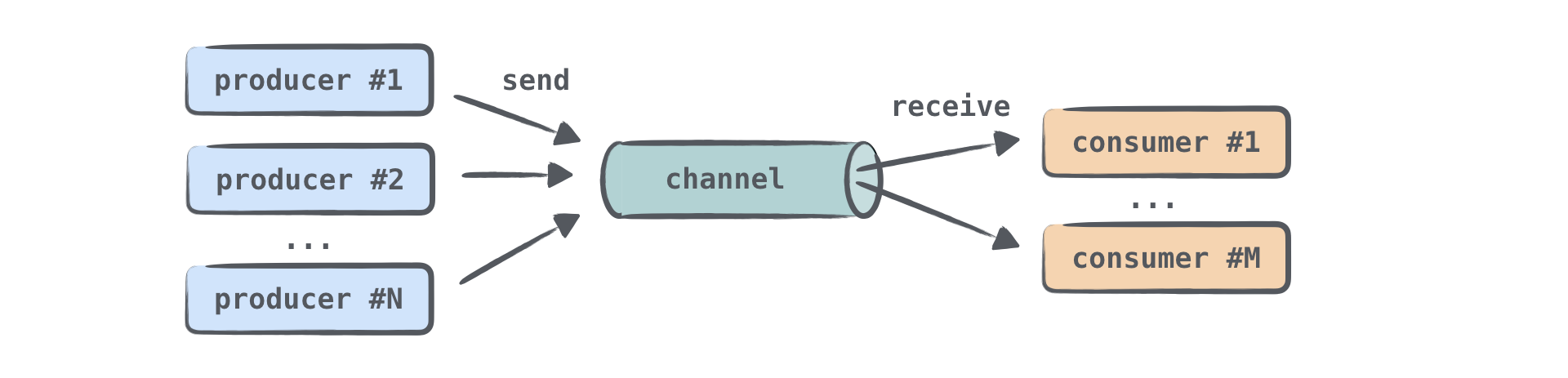
多くのコルーチンが同じチャネルから情報を受信する場合、各要素はいずれかのコンシューマーによって1回だけ処理されます。要素が処理されると、直ちにチャネルから削除されます。
チャネルは、要素のコレクション、より正確には、一方の端から要素が追加され、もう一方の端から受け取られるキューのようなものと考えることができます。しかし、重要な違いがあります。同期されたバージョンのコレクションとは異なり、チャネルは send() および receive() 操作を中断 (suspend) させることができます。これは、チャネルが空または満杯の場合に発生します。チャネルのサイズに上限がある場合、チャネルは満杯になる可能性があります。
Channel は3つの異なるインターフェースによって表されます:SendChannel、ReceiveChannel、および Channel です(最後は最初の2つを拡張したものです)。通常、チャネルを作成し、プロデューサーには SendChannel インスタンスとして渡して、プロデューサーだけがチャネルに情報を送信できるようにします。 コンシューマーには ReceiveChannel インスタンスとして渡して、コンシューマーだけがそこから受信できるようにします。send と receive の両方のメソッドは suspend として宣言されています:
interface SendChannel<in E> {
suspend fun send(element: E)
fun close(): Boolean
}
interface ReceiveChannel<out E> {
suspend fun receive(): E
}
interface Channel<E> : SendChannel<E>, ReceiveChannel<E>プロデューサーは、これ以上要素が来ないことを示すためにチャネルをクローズできます。
ライブラリにはいくつかのタイプのチャネルが定義されています。それらは、内部的に保存できる要素の数と、send() 呼び出しが中断される可能性があるかどうかによって異なります。 すべてのチャネルタイプにおいて、receive() 呼び出しは同様に動作します。チャネルが空でなければ要素を受信し、空であれば中断されます。
Unlimited channel (無制限チャネル)
無制限チャネルはキューに最も近いものです。プロデューサーはこのチャネルに要素を送信でき、チャネルは無期限に成長し続けます。send() 呼び出しが中断されることはありません。プログラムがメモリ不足になると、OutOfMemoryException が発生します。無制限チャネルとキューの違いは、コンシューマーが空のチャネルから受信しようとすると、新しい要素が送信されるまで中断されることです。

Buffered channel (バッファ付きチャネル)
バッファ付きチャネルのサイズは、指定された数によって制限されます。プロデューサーはサイズ制限に達するまでこのチャネルに要素を送信できます。すべての要素は内部的に保存されます。チャネルがいっぱいになると、空きスペースができるまで次の send() 呼び出しは中断されます。

Rendezvous channel (ランデブーチャネル)
「ランデブー」チャネルはバッファのないチャネルで、サイズがゼロのバッファ付きチャネルと同じです。一方の関数(send() または receive())は、もう一方が呼び出されるまで常に中断されます。
send() 関数が呼び出され、要素を処理する準備ができている中断された receive() 呼び出しがない場合、send() は中断されます。同様に、receive() 関数が呼び出され、チャネルが空である(つまり、要素を送信する準備ができている中断された send() 呼び出しがない)場合、receive() 呼び出しは中断されます。
「ランデブー」という名前(「合意された時間と場所での会合」)は、send() と receive() が「時間通りに出会う」必要があるという事実に由来しています。

Conflated channel (合流チャネル)
合流チャネルに送信された新しい要素は、以前に送信された要素を上書きするため、受信側は常に最新の要素のみを受け取ります。send() 呼び出しが中断されることはありません。

チャネルを作成するときは、そのタイプまたはバッファサイズ(バッファ付きが必要な場合)を指定します:
val rendezvousChannel = Channel<String>()
val bufferedChannel = Channel<String>(10)
val conflatedChannel = Channel<String>(CONFLATED)
val unlimitedChannel = Channel<String>(UNLIMITED)デフォルトでは、「ランデブー」チャネルが作成されます。
次のタスクでは、ランデブーチャネル、2つのプロデューサーコルーチン、および1つのコンシューマーコルーチンを作成します:
import kotlinx.coroutines.channels.Channel
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
val channel = Channel<String>()
launch {
channel.send("A1")
channel.send("A2")
log("A done")
}
launch {
channel.send("B1")
log("B done")
}
launch {
repeat(3) {
val x = channel.receive()
log(x)
}
}
}
fun log(message: Any?) {
println("[${Thread.currentThread().name}] $message")
}チャネルをより深く理解するために、このビデオをご覧ください。
タスク 7
src/tasks/Request7Channels.kt で、すべての GitHub コントリビューターを並行してリクエストし、同時に中間進捗を表示する loadContributorsChannels() 関数を実装してください。
以前の関数、Request5Concurrent.kt の loadContributorsConcurrent() と Request6Progress.kt の loadContributorsProgress() を活用してください。
タスク 7 のヒント
異なるリポジトリのコントリビューターリストを並行して受信する異なるコルーチンが、受信したすべての結果を同じチャネルに送信できます:
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = TODO()
// ...
channel.send(users)
}
}その後、このチャネルからの要素を1つずつ受信して処理できます:
repeat(repos.size) {
val users = channel.receive()
// ...
}receive() 呼び出しは逐次的なので、追加の同期は不要です。
タスク 7 の解決策
loadContributorsProgress() 関数と同様に、「全コントリビューター」リストの中間状態を保存する allUsers 変数を作成できます。 チャネルから受信した各新しいリストは、すべてのユーザーのリストに追加されます。結果を集計し、updateResults コールバックを使用して状態を更新します:
suspend fun loadContributorsChannels(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
channel.send(users)
}
}
var allUsers = emptyList<User>()
repeat(repos.size) {
val users = channel.receive()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, it == repos.lastIndex)
}
}- 異なるリポジトリの結果は、準備が整うとすぐにチャネルに追加されます。最初は、すべてのリクエストが送信され、データが受信されていない場合、
receive()呼び出しは中断されます。この場合、「コントリビューター読み込み」コルーチン全体が中断されます。 - その後、ユーザーリストがチャネルに送信されると、「コントリビューター読み込み」コルーチンが再開され、
receive()呼び出しはこのリストを返し、結果が直ちに更新されます。
これでプログラムを実行し、CHANNELS オプションを選択してコントリビューターを読み込み、結果を確認できます。
コルーチンもチャネルも並行性に起因する複雑さを完全に取り除くわけではありませんが、何が起きているのかを理解する必要がある場合に、作業を容易にしてくれます。
コルーチンのテスト
それでは、並行コルーチンを使用した解決策が suspend 関数を使用した解決策よりも速いこと、およびチャネルを使用した解決策が単純な「進捗」解決策よりも速いことを確認するために、すべての解決策をテストしてみましょう。
次のタスクでは、解決策の総実行時間を比較します。GitHub サービスをモックし、このサービスが指定されたタイムアウト後に結果を返すようにします:
repos リクエスト - 1000ミリ秒の遅延内に回答を返す
repo-1 - 1000ミリ秒の遅延
repo-2 - 1200ミリ秒の遅延
repo-3 - 800ミリ秒の遅延suspend 関数を使用した逐次的な解決策には、約4000ミリ秒かかるはずです (4000 = 1000 + (1000 + 1200 + 800))。 並行解決策には、約2200ミリ秒かかるはずです (2200 = 1000 + max(1000, 1200, 800))。
進捗を表示する解決策については、タイムスタンプを使用して中間結果を確認することもできます。
対応するテストデータは test/contributors/testData.kt で定義されており、Request4SuspendKtTest、Request7ChannelsKtTest などのファイルには、モックサービス呼び出しを使用する直接的なテストが含まれています。
しかし、ここには2つの問題があります:
- これらのテストは実行に時間がかかりすぎます。各テストに約2〜4秒かかり、そのたびに結果を待つ必要があります。あまり効率的ではありません。
- コードの準備と実行にさらに時間がかかるため、解決策が実行される正確な時間に頼ることはできません。定数を追加することもできますが、その時間はマシンごとに異なります。モックサービスの遅延は、違いがわかるようにこの定数よりも大きくする必要があります。定数が0.5秒の場合、遅延を0.1秒にしても十分ではありません。
より良い方法は、同じコードを数回実行しながらタイミングをテストする特別なフレームワークを使用することですが(これにより総時間はさらに長くなります)、それは学習とセットアップが複雑です。
これらの問題を解決し、提供されたテスト遅延を伴う解決策が、一方が他方より速いという期待通りの動作をすることを確認するには、特別なテストディスパッチャを備えた仮想 (virtual) 時間を使用します。このディスパッチャは、開始からの経過仮想時間を追跡し、リアルタイムですべてを即座に実行します。このディスパッチャ上でコルーチンを実行すると、delay は即座に値を返し、仮想時間を進めます。
このメカニズムを使用したテストは高速に実行されますが、仮想時間の異なる瞬間で何が起こるかを確認することは可能です。総実行時間は劇的に短縮されます:

仮想時間を使用するには、runBlocking の呼び出しを runTest に置き換えます。runTest は TestScope への拡張ラムダを引数として受け取ります。 この特別なスコープ内の中断関数で delay を呼び出すと、delay はリアルタイムで遅延させる代わりに仮想時間を増加させます:
@Test
fun testDelayInSuspend() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
foo()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 6 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun foo() {
delay(1000) // 遅延なしで自動的に進む
println("foo") // foo() が呼び出されるとすぐに実行される
}TestScope の currentTime プロパティを使用して、現在の仮想時間を確認できます。
この例の実際の実行時間は数ミリ秒ですが、仮想時間は delay 引数である1000ミリ秒に等しくなります。
子コルーチンで「仮想」delay の完全な効果を得るには、 すべての子供コルーチンを TestDispatcher で開始する必要があります。そうしないと機能しません。別のディスパッチャを提供しない限り、このディスパッチャは他の TestScope から自動的に継承されます:
@Test
fun testDelayInLaunch() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
bar()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 11 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun bar() = coroutineScope {
launch {
delay(1000) // 遅延なしで自動的に進む
println("bar") // bar() が呼び出されるとすぐに実行される
}
}上記の例で launch が Dispatchers.Default のコンテキストで呼び出されると、テストは失敗します。ジョブがまだ完了していないという例外が発生します。
loadContributorsConcurrent() 関数をこの方法でテストできるのは、継承されたコンテキストで子コルーチンを開始する場合のみです。Dispatchers.Default ディスパッチャを使用してコンテキストを変更してはいけません。
ディスパッチャのようなコンテキスト要素は、関数を定義するときではなく呼び出すときに指定できるため、柔軟性が高まり、テストが容易になります。
仮想時間をサポートするテスト API は試験的 (Experimental) であり、将来変更される可能性があります。
デフォルトでは、試験的なテスト API を使用するとコンパイラは警告を表示します。これらの警告を抑制するには、テスト関数またはテストを含むクラス全体に @OptIn(ExperimentalCoroutinesApi::class) アノテーションを付けます。 試験的な API を使用していることをコンパイラに通知するコンパイラ引数を追加します:
compileTestKotlin {
kotlinOptions {
freeCompilerArgs += "-Xuse-experimental=kotlin.Experimental"
}
}このチュートリアルに対応するプロジェクトでは、コンパイラ引数はすでに Gradle スクリプトに追加されています。
タスク 8
tests/tasks/ 内の以下のテストを、リアルタイムではなく仮想時間を使用するようにリファクタリングしてください:
Request4SuspendKtTest.ktRequest5ConcurrentKtTest.ktRequest6ProgressKtTest.ktRequest7ChannelsKtTest.kt
リファクタリングを適用する前と後の総実行時間を比較してください。
タスク 8 のヒント
runBlockingの呼び出しをrunTestに置き換え、System.currentTimeMillis()をcurrentTimeに置き換えます:kotlin@Test fun test() = runTest { val startTime = currentTime // アクション val totalTime = currentTime - startTime // 結果のテスト }正確な仮想時間を確認するアサーションのコメントを解除します。
@UseExperimental(ExperimentalCoroutinesApi::class)を忘れずに追加してください。
タスク 8 の解決策
並行ケースとチャネルケースの解決策は次のとおりです:
fun testConcurrent() = runTest {
val startTime = currentTime
val result = loadContributorsConcurrent(MockGithubService, testRequestData)
Assert.assertEquals("Wrong result for 'loadContributorsConcurrent'", expectedConcurrentResults.users, result)
val totalTime = currentTime - startTime
Assert.assertEquals(
"呼び出しは並行して実行されるため、総仮想時間は 2200 ms である必要があります: " +
"repos リクエストに 1000、さらに並行コントリビューターリクエストに max(1000, 1200, 800) = 1200",
expectedConcurrentResults.timeFromStart, totalTime
)
}まず、結果が期待される仮想時間に正確に入手可能であることを確認し、次に結果自体を確認します:
fun testChannels() = runTest {
val startTime = currentTime
var index = 0
loadContributorsChannels(MockGithubService, testRequestData) { users, _ ->
val expected = concurrentProgressResults[index++]
val time = currentTime - startTime
Assert.assertEquals(
"期待される中間結果までの時間 ${expected.timeFromStart} ms:",
expected.timeFromStart, time
)
Assert.assertEquals("中間結果の誤り $time:", expected.users, users)
}
}チャネルを使用した最後のバージョンの最初の中間結果は、進捗バージョンよりも早く入手可能になり、仮想時間を使用するテストでその違いを確認できます。
残りの "suspend" および "progress" タスクのテストも非常によく似ています。プロジェクトの
solutionsブランチで見つけることができます。
次のステップ
- KotlinConf の Asynchronous Programming with Kotlin ワークショップをチェックしてください。
- 仮想時間と試験的なテストパッケージの使用について詳しく学びましょう。