ウェブソースや API からデータを取得する
Kotlin Notebook は、さまざまなウェブソースや API からデータにアクセスして操作するための強力なプラットフォームを提供します。 すべてのステップを視覚化して明確にできるイテレーティブ(反復的)な環境を提供することで、データの抽出や分析タスクを簡素化します。これは、馴染みのない API を探索する際に特に役立ちます。
Kotlin DataFrame ライブラリと併用することで、Kotlin Notebook は API から JSON データを接続・取得できるだけでなく、包括的な分析や視覚化のためにデータを再形成する際にも役立ちます。
Kotlin Notebook の例については、GitHub の DataFrame の例を参照してください。
始める前に
Kotlin Notebook は、IntelliJ IDEA にデフォルトで同梱・有効化されている Kotlin Notebook プラグインに依存しています。
Kotlin Notebook の機能が利用できない場合は、プラグインが有効になっていることを確認してください。詳細については、環境のセットアップを参照してください。
新しい Kotlin Notebook を作成します:
File | New | Kotlin Notebook を選択します。
Kotlin Notebook で、次のコマンドを実行して Kotlin DataFrame ライブラリをインポートします。
kotlin%use dataframe
API からデータを取得する
Kotlin Notebook と Kotlin DataFrame ライブラリを使用して API からデータを取得するには、.read() 関数を使用します。これは、CSV や JSON などの ファイルからのデータ取得 と同様です。 ただし、ウェブベースのソースを扱う場合は、生の API データを構造化された形式に変換するために、追加のフォーマットが必要になる場合があります。
YouTube Data API からデータを取得する例を見てみましょう:
Kotlin Notebook ファイル (
.ipynb) を開きます。データ操作タスクに不可欠な Kotlin DataFrame ライブラリをインポートします。 これを行うには、コードセルで次のコマンドを実行します:
kotlin%use dataframeYouTube Data API へのリクエストを認証するために必要な API キーを、新しいコードセルに安全に追加します。 API キーは 認証情報タブ から取得できます:
kotlinval apiKey = "YOUR-API_KEY"パスを文字列として受け取り、DataFrame の
.read()関数を使用して YouTube Data API からデータを取得する load 関数を作成します:kotlinfun load(path: String): AnyRow = DataRow.read("https://www.googleapis.com/youtube/v3/$path&key=$apiKey")取得したデータを行に整理し、
nextPageTokenを介して YouTube API のページネーションを処理します。 これにより、複数のページにわたるデータを確実に収集できます:kotlinfun load(path: String, maxPages: Int): AnyFrame { // データ行を格納するためのミュータブルなリストを初期化します。 val rows = mutableListOf<AnyRow>() // データ読み込みの初期ページパスを設定します。 var pagePath = path do { // 現在のページパスからデータを読み込みます。 val row = load(pagePath) // 読み込んだデータを行としてリストに追加します。 rows.add(row) // 利用可能な場合、次のページのトークンを取得します。 val next = row.getValueOrNull<String>("nextPageToken") // 新しいトークンを含めて、次回のイテレーション用のページパスを更新します。 pagePath = path + "&pageToken=" + next // 次のページがなくなるまで、ページの読み込みを続けます。 } while (next != null && rows.size < maxPages) // 読み込まれたすべての行を連結し、DataFrame として返します。 return rows.concat() }以前に定義した
load()関数を使用してデータを取得し、新しいコードセルで DataFrame を作成します。 この例では、Kotlin に関連するデータ(この場合は動画)を取得し、1 ページあたり最大 50 件の結果を最大 5 ページまで取得します。 結果はdf変数に格納されます:kotlinval df = load("search?q=kotlin&maxResults=50&part=snippet", 5) df最後に、DataFrame からアイテムを抽出して結合します:
kotlinval items = df.items.concat() items
データのクリーニングと精製
データのクリーニングと精製は、分析用にデータセットを準備する上で重要なステップです。Kotlin DataFrame ライブラリ は、これらのタスクのための強力な機能を提供します。move、concat、select、parse、join といったメソッドは、データの整理や変換に役立ちます。
YouTube の Data API を使用して既に取得されたデータ を例に見てみましょう。 ここでの目標は、詳細な分析に備えてデータセットをクリーニングし、再構築することです:
まず、データの再構成とクリーニングから始めることができます。これには、特定の列を新しいヘッダーの下に移動したり、明確にするために不要な列を削除したりすることが含まれます:
kotlinval videos = items.dropNulls { id.videoId } .select { id.videoId named "id" and snippet } .distinct() videosクリーニングされたデータから ID をチャンク化し、対応する動画の統計情報を読み込みます。これには、データを小さなバッチに分割し、追加の詳細を取得することが含まれます:
kotlinval statPages = clean.id.chunked(50).map { val ids = it.joinToString("%2C") load("videos?part=statistics&id=$ids") } statPages取得した統計情報を連結し、関連する列を選択します:
kotlinval stats = statPages.items.concat().select { id and statistics.all() }.parse() stats既存のクリーニング済みデータと、新しく取得した統計情報を結合します。これにより、2 つのデータセットが包括的な DataFrame に統合されます:
kotlinval joined = clean.join(stats) joined
この例は、Kotlin DataFrame のさまざまな関数を使用して、データセットをクリーニング、再構成、および強化する方法を示しています。 各ステップはデータを精製するように設計されており、詳細な分析 に適した状態にします。
Kotlin Notebook でデータを分析する
Kotlin DataFrame ライブラリ の関数を使用して、データの取得 と データのクリーニングと精製 が正常に完了したら、次のステップはこの準備されたデータセットを分析して、有意義な洞察を引き出すことです。
データをカテゴリ分けするための groupBy、要約統計量 のための sum や maxBy、データを並べ替えるための sortBy といったメソッドが特に便利です。 これらのツールを使用すると、複雑なデータ分析タスクを効率的に実行できます。
groupBy を使用して動画をチャンネルごとにカテゴリ分けし、sum を使用してカテゴリごとの総視聴回数を計算し、maxBy を使用して各グループ内の最新または最も視聴された動画を見つける例を見てみましょう:
参照を設定して、特定の列へのアクセスを簡素化します:
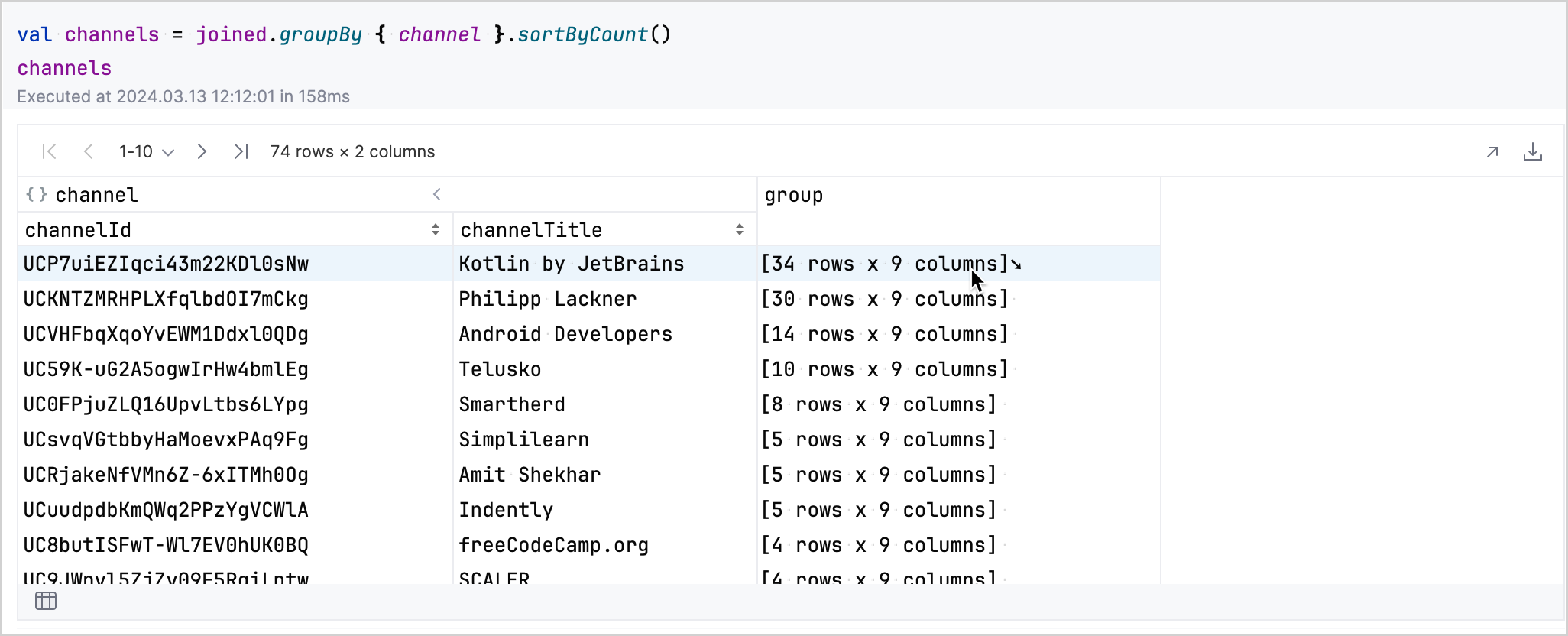
kotlinval view by column<Int>()groupByメソッドを使用してchannel列でデータをグループ化し、ソートします。kotlinval channels = joined.groupBy { channel }.sortByCount()
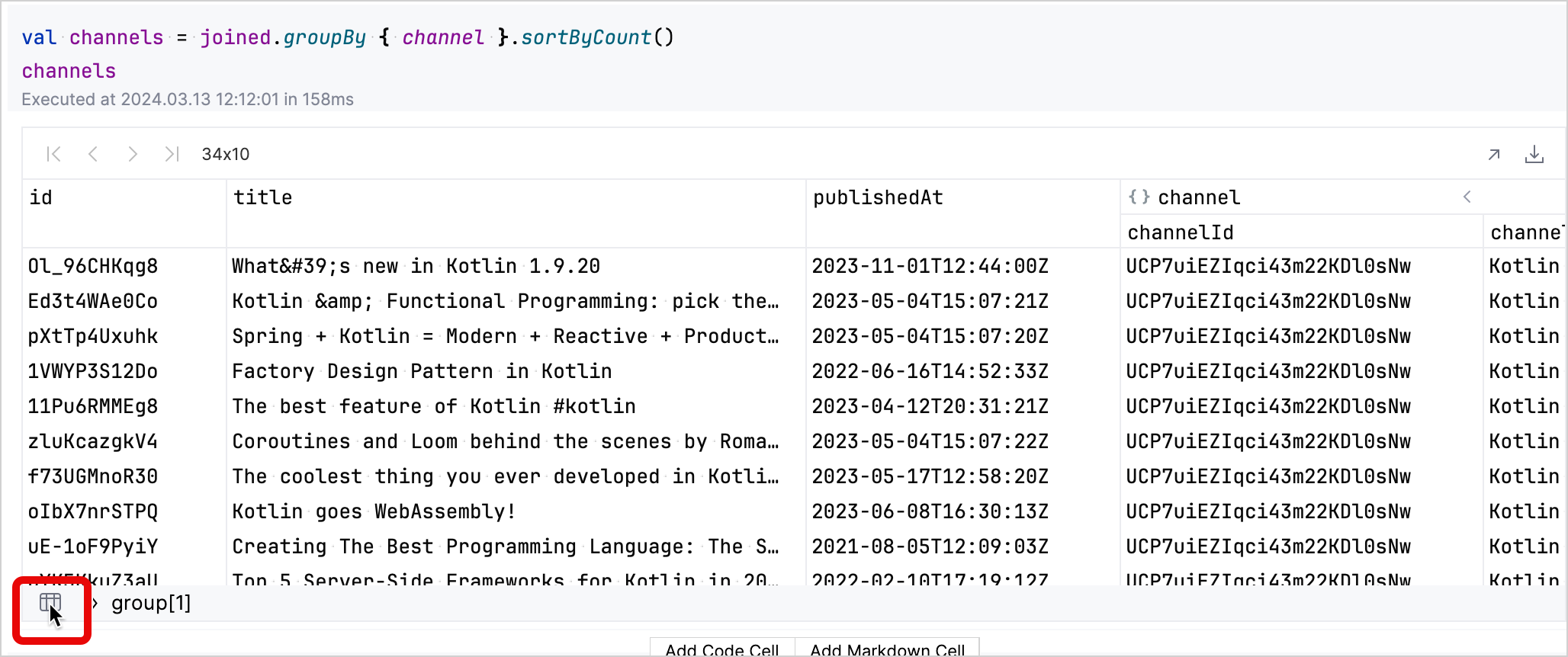
生成されたテーブルでは、対話的にデータを探索できます。チャンネルに対応する行の group フィールドをクリックすると、その行が展開され、そのチャンネルの動画に関する詳細が表示されます。
左下のテーブルアイコンをクリックすると、グループ化されたデータセットに戻ることができます。
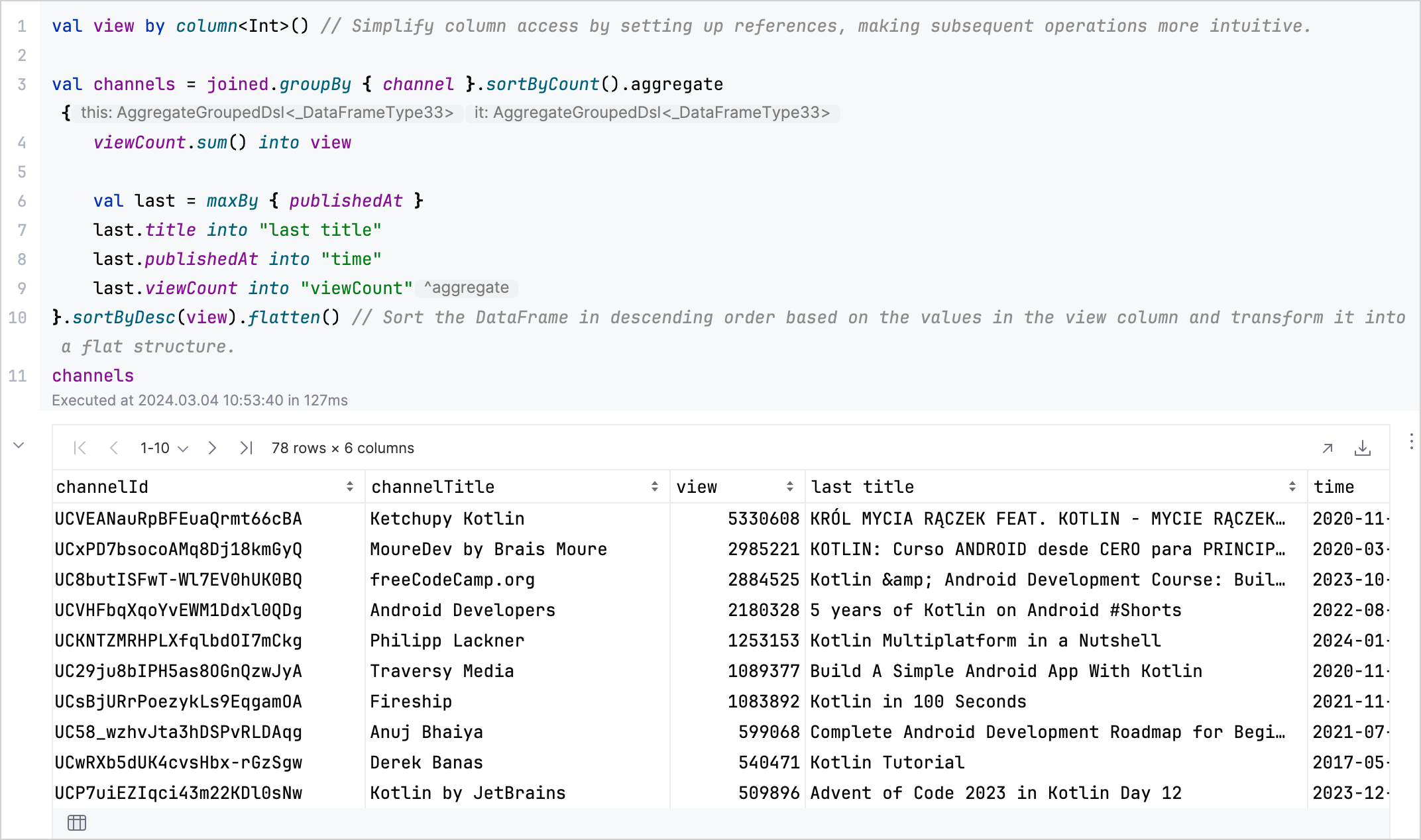
aggregate、sum、maxBy、flattenを使用して、各チャンネルの総視聴回数と、その最新または最も視聴された動画の詳細をまとめた DataFrame を作成します:kotlinval aggregated = channels.aggregate { viewCount.sum() into view val last = maxBy { publishedAt } last.title into "last title" last.publishedAt into "time" last.viewCount into "viewCount" // 視聴回数の降順で DataFrame をソートし、フラットな構造に変換します。 }.sortByDesc(view).flatten() aggregated
分析の結果:
より高度なテクニックについては、Kotlin DataFrame のドキュメント を参照してください。
次のステップ
- Kandy ライブラリ を使用したデータの視覚化を探索する
- Kandy を使用した Kotlin Notebook でのデータの視覚化 で、データの視覚化に関する追加情報を見つける
- Kotlin でのデータサイエンスと分析に利用可能なツールとリソースの広範な概要については、データ分析用の Kotlin および Java ライブラリ を参照してください。