从 Web 源和 API 检索数据
Kotlin Notebook 为访问和操作来自各种 Web 源及 API 的数据提供了一个强大的平台。它通过提供一个迭代环境,简化了数据提取和分析任务,在其中可以可视化每一步以确保清晰。这在探索不熟悉的 API 时特别有用。
当与 Kotlin DataFrame 库配合使用时,Kotlin Notebook 不仅能让您连接并从 API 获取 JSON 数据,还能协助重构这些数据,以进行全面的分析和可视化。
有关 Kotlin Notebook 示例,请参阅 GitHub 上的 DataFrame 示例。
开始之前
Kotlin Notebook 依赖于 Kotlin Notebook 插件,该插件在 IntelliJ IDEA 中默认捆绑并启用。
如果 Kotlin Notebook 功能不可用,请确保该插件已启用。要了解更多信息,请参阅设置环境。
创建一个新的 Kotlin Notebook:
选择 File | New | Kotlin Notebook。
在 Kotlin Notebook 中,通过运行以下命令导入 Kotlin DataFrame 库:
kotlin%use dataframe
从 API 获取数据
使用 Kotlin Notebook 与 Kotlin DataFrame 库从 API 获取数据是通过 .read() 函数实现的,这与从文件检索数据(如 CSV 或 JSON)类似。然而,在处理基于 Web 的源时,您可能需要额外的格式设置,以将原始 API 数据转换为结构化格式。
让我们来看一个从 YouTube Data API 获取数据的示例:
打开您的 Kotlin Notebook 文件 (
.ipynb)。导入对数据操作任务至关重要的 Kotlin DataFrame 库。这可以通过在代码单元格中运行以下命令来完成:
kotlin%use dataframe在新的代码单元格中安全地添加您的 API 密钥,这是对 YouTube Data API 请求进行身份验证所必需的。您可以从凭据选项卡获取您的 API 密钥:
kotlinval apiKey = "YOUR-API_KEY"创建一个
load函数,该函数接收一个字符串路径,并使用 DataFrame 的.read()函数从 YouTube Data API 获取数据:kotlinfun load(path: String): AnyRow = DataRow.read("https://www.googleapis.com/youtube/v3/$path&key=$apiKey")将获取的数据整理成行,并通过
nextPageToken处理 YouTube API 的分页。这可确保您收集跨多个页面的数据:kotlinfun load(path: String, maxPages: Int): AnyFrame { // 初始化一个可变列表以存储数据行。 val rows = mutableListOf<AnyRow>() // 设置用于数据加载的初始页面路径。 var pagePath = path do { // 从当前页面路径加载数据。 val row = load(pagePath) // 将加载的数据作为一行添加到列表中。 rows.add(row) // 检索下一页的令牌(如果可用)。 val next = row.getValueOrNull<String>("nextPageToken") // 更新下一轮迭代的页面路径,包括新的令牌。 pagePath = path + "&pageToken=" + next // 继续加载页面,直到没有下一页。 } while (next != null && rows.size < maxPages) // 串联并以 DataFrame 形式返回所有加载的行。 return rows.concat() }使用先前定义的
load()函数在新的代码单元格中获取数据并创建 DataFrame。本例获取了与 Kotlin 相关的视频数据,每页最多 50 个结果,最多获取 5 页。结果存储在df变量中:kotlinval df = load("search?q=kotlin&maxResults=50&part=snippet", 5) df最后,从 DataFrame 中提取并串联项目:
kotlinval items = df.items.concat() items
清理与提炼数据
清理与提炼数据是准备分析数据集的关键步骤。Kotlin DataFrame 库为这些任务提供了强大的功能。move、concat、select、parse 和 join 等方法在组织和转换数据方面发挥着重要作用。
让我们探讨一个示例,其中的数据已经使用 YouTube 的数据 API 获取。目标是清理并重构数据集,为深入分析做准备:
您可以从重新组织和清理数据开始。这包括将某些列移至新标题下,并移除不必要的列以确保清晰:
kotlinval videos = items.dropNulls { id.videoId } .select { id.videoId named "id" and snippet } .distinct() videos从清理后的数据中分块获取 ID,并加载相应的视频统计信息。这涉及将数据分解为较小的批次并获取额外详情:
kotlinval statPages = clean.id.chunked(50).map { val ids = it.joinToString("%2C") load("videos?part=statistics&id=$ids") } statPages串联获取的统计信息并选择相关列:
kotlinval stats = statPages.items.concat().select { id and statistics.all() }.parse() stats将现有的清理数据与新获取的统计信息进行连接。这会将两组数据合并为一个全面的 DataFrame:
kotlinval joined = clean.join(stats) joined
此示例演示了如何使用 Kotlin DataFrame 的各种函数来清理、重组和增强您的数据集。每一步都旨在提炼数据,使其更适合深入分析。
在 Kotlin Notebook 中分析数据
在成功使用 Kotlin DataFrame 库的功能获取并清理和提炼数据后,下一步是分析准备好的数据集,以提取有意义的洞察。
诸如用于数据分类的 groupBy、用于摘要统计的 sum 和 maxBy,以及用于数据排序的 sortBy 等方法特别有用。这些工具允许您高效地执行复杂的数据分析任务。
让我们看一个示例,使用 groupBy 按频道对视频进行分类,使用 sum 计算每个类别的总观看次数,并使用 maxBy 查找每个组中最新或观看次数最多的视频:
通过设置引用简化对特定列的访问:
kotlinval view by column<Int>()使用
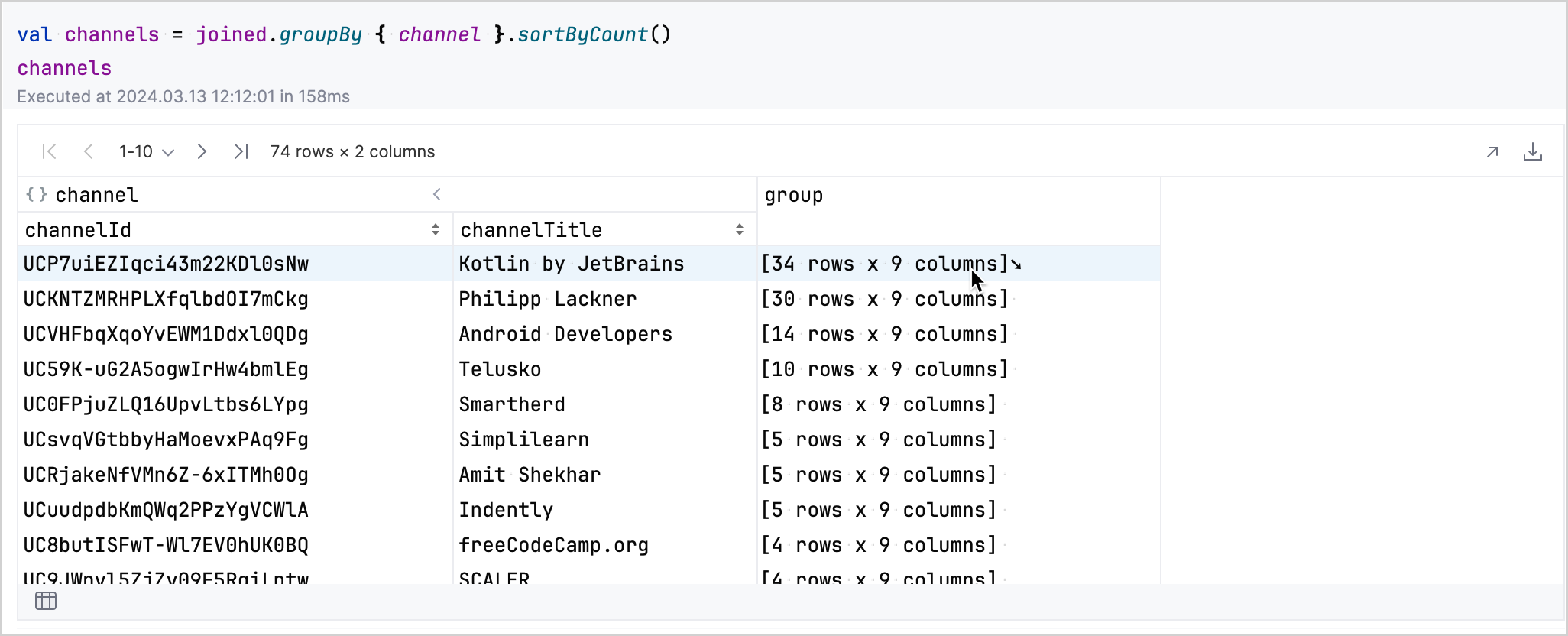
groupBy方法按channel列对数据进行分组并进行排序。kotlinval channels = joined.groupBy { channel }.sortByCount()
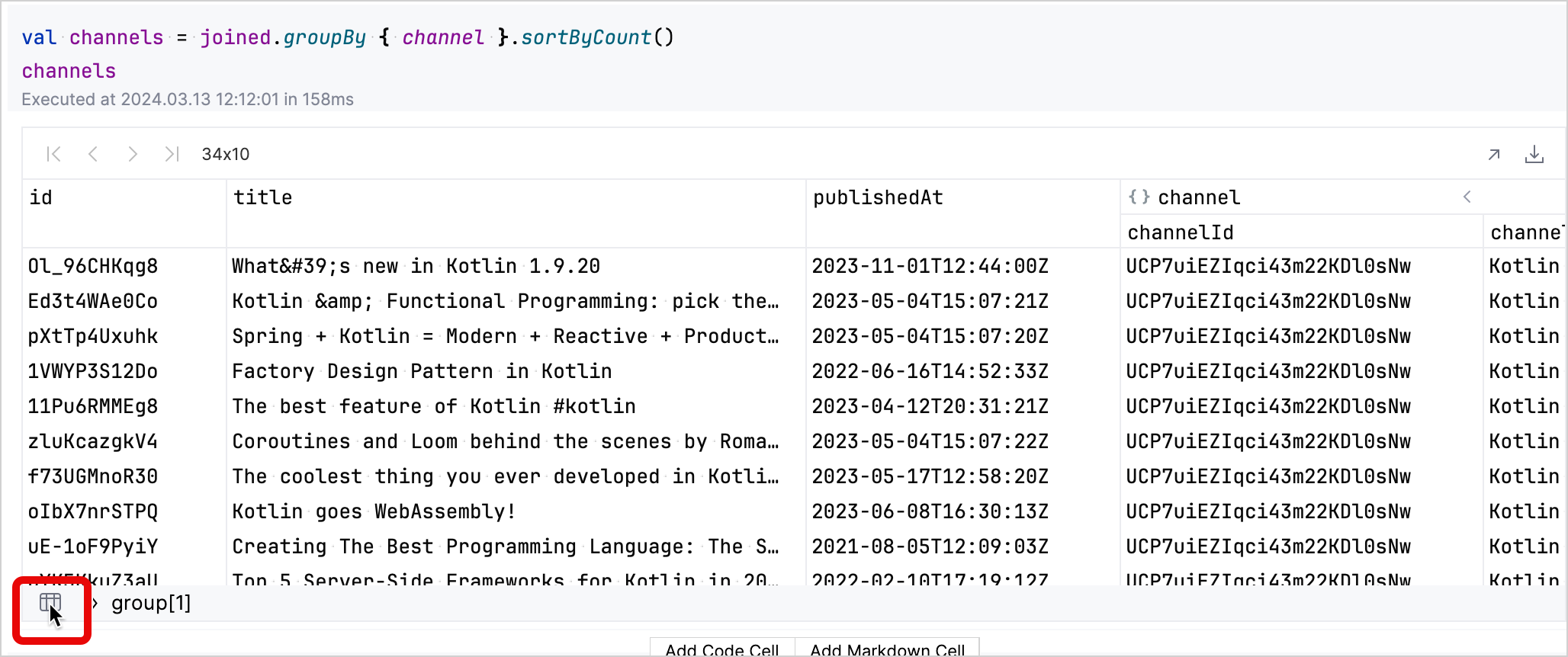
在生成的表格中,您可以交互式地探索数据。点击频道对应行的 group 字段会展开该行,以显示有关该频道视频的更多详情。
您可以点击左下角的表格图标返回到分组后的数据集。
使用
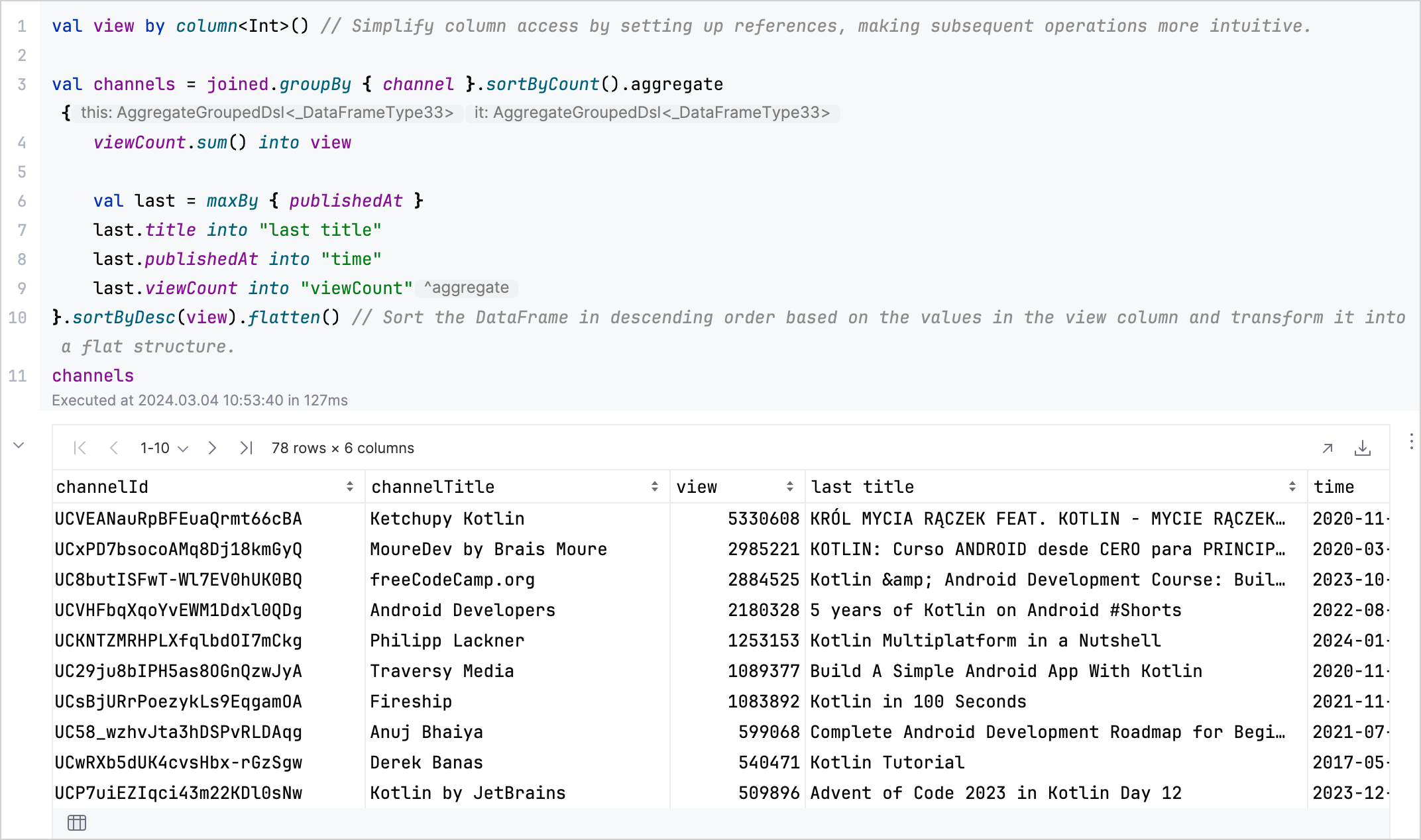
aggregate、sum、maxBy和flatten创建一个 DataFrame,总结每个频道的总观看次数以及其最新或观看次数最多的视频的详情:kotlinval aggregated = channels.aggregate { viewCount.sum() into view val last = maxBy { publishedAt } last.title into "last title" last.publishedAt into "time" last.viewCount into "viewCount" // 按观看次数降序排列 DataFrame 并将其转换为扁平结构。 }.sortByDesc(view).flatten() aggregated
分析结果:
有关更多高级技术,请参阅 Kotlin DataFrame 文档。
下一步
- 使用 Kandy 库探索数据可视化
- 在使用 Kandy 在 Kotlin Notebook 中进行数据可视化中查找有关数据可视化的其他信息
- 有关 Kotlin 中可用于数据科学和分析的工具和资源的广泛概述,请参阅用于数据分析的 Kotlin 和 Java 库