從 Web 來源與 API 獲取資料
Kotlin Notebook 提供了一個強大的平台,用於存取和處理來自各種 Web 來源與 API 的資料。它透過提供一個可以視覺化每個步驟以確保清晰度的迭代環境,簡化了資料擷取與分析任務。這在探索您不熟悉的 API 時特別有用。
當與 Kotlin DataFrame 程式庫 配合使用時,Kotlin Notebook 不僅能讓您連線並從 API 獲取 JSON 資料,還能協助重構這些資料以進行全面的分析與視覺化。
有關 Kotlin Notebook 範例,請參閱 GitHub 上的 DataFrame 範例。
開始之前
Kotlin Notebook 依賴於 Kotlin Notebook 外掛程式,該外掛程式預設在 IntelliJ IDEA 中封裝並啟用。
如果 Kotlin Notebook 功能不可用,請確保外掛程式已啟用。欲了解更多資訊,請參閱設定環境。
建立新的 Kotlin Notebook:
選取 File | New | Kotlin Notebook。
在 Kotlin Notebook 中,透過執行以下指令匯入 Kotlin DataFrame 程式庫:
kotlin%use dataframe
從 API 獲取資料
使用 Kotlin Notebook 搭配 Kotlin DataFrame 程式庫從 API 獲取資料是透過 .read() 函式完成的,這與從檔案獲取資料(如 CSV 或 JSON)類似。然而,在處理基於 Web 的來源時,您可能需要額外的格式化來將原始 API 資料轉換為結構化格式。
讓我們看一個從 YouTube Data API 獲取資料的範例:
開啟您的 Kotlin Notebook 檔案 (
.ipynb)。匯入 Kotlin DataFrame 程式庫,這對於資料處理任務至關重要。這是在程式碼資料格中執行以下指令來完成的:
kotlin%use dataframe在新的程式碼資料格中安全地加入您的 API 金鑰,這對於驗證 YouTube Data API 的請求是必要的。您可以從憑據分頁獲取您的 API 金鑰:
kotlinval apiKey = "YOUR-API_KEY"建立一個 load 函式,該函式接收一個字串形式的路徑,並使用 DataFrame 的
.read()函式從 YouTube Data API 獲取資料:kotlinfun load(path: String): AnyRow = DataRow.read("https://www.googleapis.com/youtube/v3/$path&key=$apiKey")將獲取的資料組織成列,並透過
nextPageToken處理 YouTube API 的分頁。這能確保您收集跨多個頁面的資料:kotlinfun load(path: String, maxPages: Int): AnyFrame { // 初始化一個可變清單來儲存資料列。 val rows = mutableListOf<AnyRow>() // 設定資料載入的初始頁面路徑。 var pagePath = path do { // 從當前頁面路徑載入資料。 val row = load(pagePath) // 將載入的資料作為一列加入清單。 rows.add(row) // 獲取下一頁的權杖(如果有的話)。 val next = row.getValueOrNull<String>("nextPageToken") // 更新下一輪迭代的頁面路徑,包含新的權杖。 pagePath = path + "&pageToken=" + next // 繼續載入頁面,直到沒有下一頁為止。 } while (next != null && rows.size < maxPages) // 串接並回傳所有載入的列作為一個 DataFrame。 return rows.concat() }使用先前定義的
load()函式獲取資料,並在新的程式碼資料格中建立一個 DataFrame。本範例獲取與 Kotlin 相關的資料(在此案例中為影片),每頁最多 50 個結果,最多 5 頁。結果儲存在df變數中:kotlinval df = load("search?q=kotlin&maxResults=50&part=snippet", 5) df最後,從 DataFrame 中擷取並串接項目:
kotlinval items = df.items.concat() items
清理與精煉資料
清理與精煉資料是準備資料集以進行分析的關鍵步驟。Kotlin DataFrame 程式庫 為這些任務提供了強大的功能。move、concat、select、parse 和 join 等方法有助於組織和轉換您的資料。
讓我們探索一個範例,其中的資料已經使用 YouTube Data API 獲取。目標是清理並重構資料集,為深入分析做準備:
您可以從重新組織和清理資料開始。這涉及將某些欄位移動到新的標頭下,並移除不必要的欄位以提高清晰度:
kotlinval videos = items.dropNulls { id.videoId } .select { id.videoId named "id" and snippet } .distinct() videos從清理後的資料中分塊 ID,並載入對應的影片統計數據。這涉及將資料分成較小的批次並獲取額外細節:
kotlinval statPages = clean.id.chunked(50).map { val ids = it.joinToString("%2C") load("videos?part=statistics&id=$ids") } statPages串接獲取的統計數據並選取相關欄位:
kotlinval stats = statPages.items.concat().select { id and statistics.all() }.parse() stats將現有的清理後資料與新獲取的統計數據合併。這會將兩組資料合併為一個全面的 DataFrame:
kotlinval joined = clean.join(stats) joined
本範例展示了如何使用 Kotlin DataFrame 的各種函式來清理、重新組織和增強您的資料集。每個步驟都旨在精煉資料,使其更適合進行深入分析。
在 Kotlin Notebook 中分析資料
在使用 Kotlin DataFrame 程式庫 的函式成功獲取並清理與精煉資料後,下一步是分析此準備好的資料集以擷取有意義的洞察。
用於將資料分類的 groupBy、用於摘要統計資料的 sum 和 maxBy,以及用於排序資料的 sortBy 等方法特別有用。這些工具讓您能有效率地執行複雜的資料分析任務。
讓我們看一個範例,使用 groupBy 按頻道對影片進行分類,使用 sum 計算每個類別的總觀看次數,並使用 maxBy 尋找每個群組中最新或觀看次數最多的影片:
透過設定參考來簡化對特定欄位的存取:
kotlinval view by column<Int>()使用
groupBy方法按channel欄位對資料進行分群並進行排序。kotlinval channels = joined.groupBy { channel }.sortByCount()
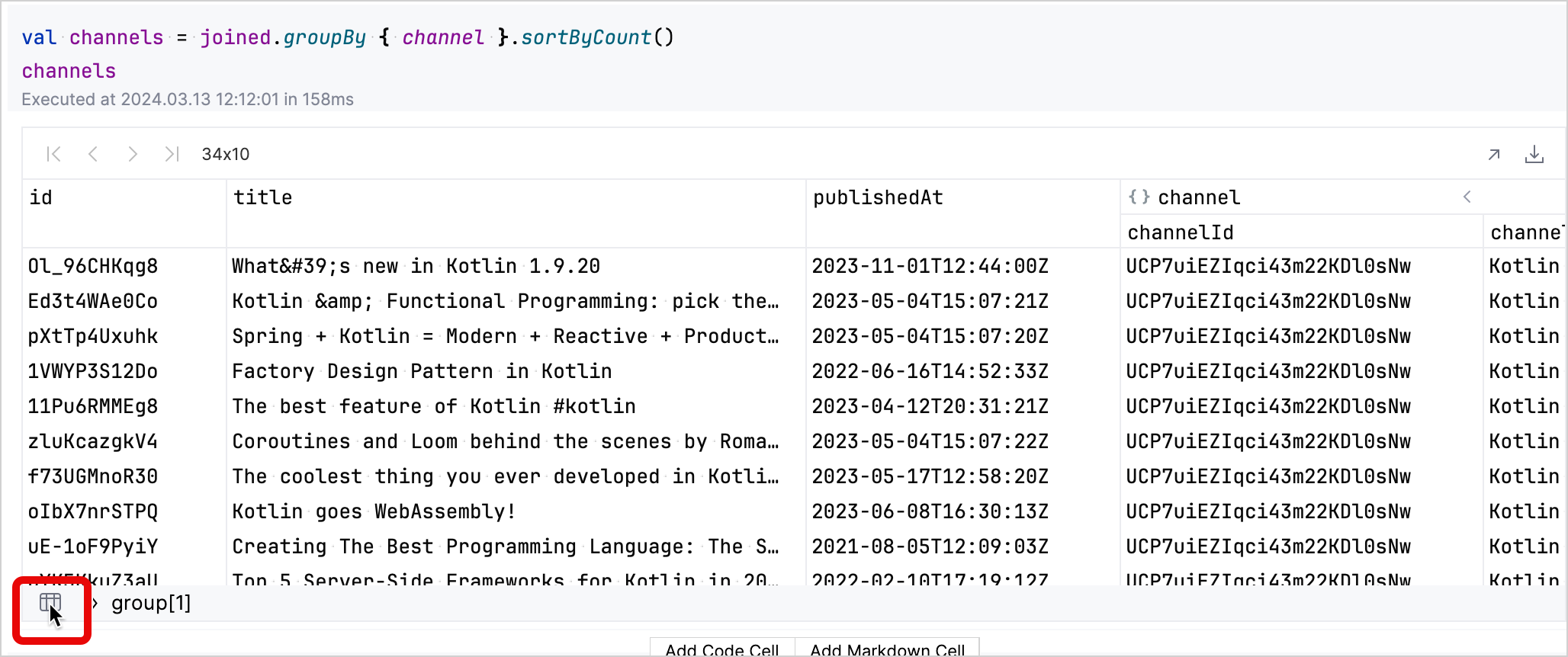
在生成的表格中,您可以互動式地探索資料。點擊對應頻道列的 group 欄位會展開該列,以顯示有關該頻道影片的更多細節。
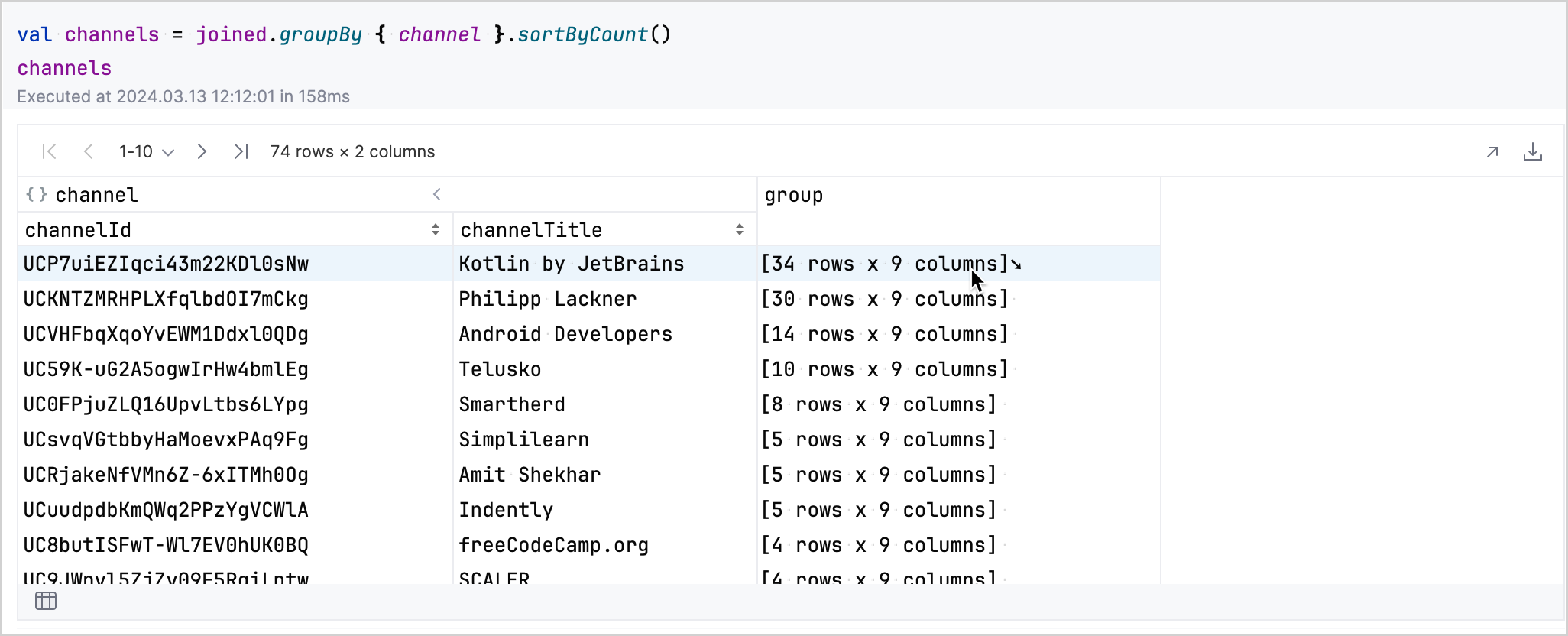
您可以點擊左下角的表格圖示回到分組後的資料集。
使用
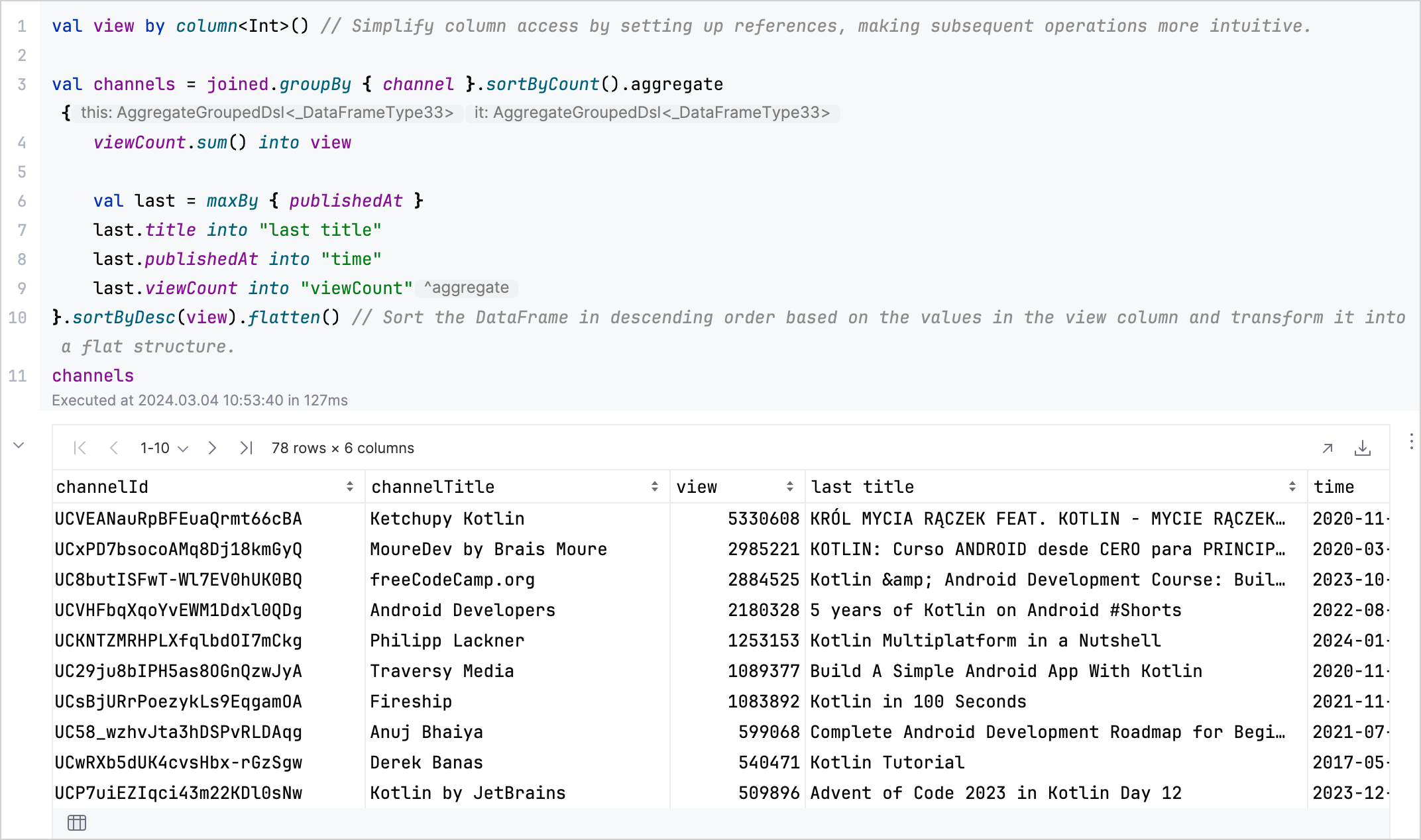
aggregate、sum、maxBy和flatten來建立一個 DataFrame,摘要每個頻道的總觀看次數以及其最新或觀看次數最多影片的細節:kotlinval aggregated = channels.aggregate { viewCount.sum() into view val last = maxBy { publishedAt } last.title into "last title" last.publishedAt into "time" last.viewCount into "viewCount" // 按觀看次數降序排列 DataFrame 並將其轉換為扁平結構。 }.sortByDesc(view).flatten() aggregated
分析結果:
如需更多進階技術,請參閱 Kotlin DataFrame 文件。
接續步驟
- 探索使用 Kandy 程式庫 進行資料視覺化
- 在 Kotlin Notebook 中使用 Kandy 進行資料視覺化中尋找有關資料視覺化的額外資訊
- 有關 Kotlin 中可用於資料科學與分析的工具和資源的廣泛概覽,請參閱 Kotlin 與 Java 資料分析程式庫