웹 소스 및 API에서 데이터 가져오기
Kotlin Notebook은 다양한 웹 소스와 API의 데이터를 액세스하고 조작할 수 있는 강력한 플랫폼을 제공합니다. 데이터 추출 및 분석 작업의 모든 단계를 시각화하여 명확하게 확인할 수 있는 반복적인(iterative) 환경을 제공함으로써 작업을 단순화합니다. 이는 특히 익숙하지 않은 API를 탐색할 때 유용합니다.
Kotlin DataFrame 라이브러리와 함께 사용하면, Kotlin Notebook을 통해 API에서 JSON 데이터를 연결하고 가져올 수 있을 뿐만 아니라, 종합적인 분석 및 시각화를 위해 이 데이터를 재구성(reshaping)하는 데에도 도움을 받을 수 있습니다.
Kotlin Notebook 예제는 GitHub의 DataFrame 예제를 참조하세요.
시작하기 전에
Kotlin Notebook은 IntelliJ IDEA에 기본적으로 포함되어 활성화되어 있는 Kotlin Notebook 플러그인에 의존합니다.
Kotlin Notebook 기능을 사용할 수 없는 경우 플러그인이 활성화되어 있는지 확인하세요. 자세한 내용은 환경 설정을 참조하세요.
새 Kotlin Notebook을 생성합니다:
File | New | Kotlin Notebook을 선택합니다.
Kotlin Notebook에서 다음 명령을 실행하여 Kotlin DataFrame 라이브러리를 임포트합니다:
kotlin%use dataframe
API에서 데이터 가져오기
Kotlin DataFrame 라이브러리가 포함된 Kotlin Notebook을 사용하여 API에서 데이터를 가져오는 것은 CSV 또는 JSON과 같은 파일에서 데이터를 검색하는 것과 유사한 .read() 함수를 통해 이루어집니다. 하지만 웹 기반 소스를 다룰 때는 원시(raw) API 데이터를 구조화된 형식으로 변환하기 위해 추가적인 포맷팅이 필요할 수 있습니다.
YouTube Data API에서 데이터를 가져오는 예제를 살펴보겠습니다:
Kotlin Notebook 파일(
.ipynb)을 엽니다.데이터 조작 작업에 필수적인 Kotlin DataFrame 라이브러리를 임포트합니다. 코드 셀에서 다음 명령을 실행하면 됩니다:
kotlin%use dataframe새 코드 셀에 API 키를 안전하게 추가합니다. 이는 YouTube Data API 요청을 인증하는 데 필요합니다. API 키는 사용자 인증 정보 탭에서 얻을 수 있습니다:
kotlinval apiKey = "YOUR-API_KEY"경로를 문자열로 받아 DataFrame의
.read()함수를 사용하여 YouTube Data API에서 데이터를 가져오는 로드 함수를 생성합니다:kotlinfun load(path: String): AnyRow = DataRow.read("https://www.googleapis.com/youtube/v3/$path&key=$apiKey")가져온 데이터를 행(row)으로 구성하고
nextPageToken을 통해 YouTube API의 페이지네이션(pagination)을 처리합니다. 이를 통해 여러 페이지에 걸친 데이터를 수집할 수 있습니다:kotlinfun load(path: String, maxPages: Int): AnyFrame { // 데이터 행을 저장할 가변 리스트를 초기화합니다. val rows = mutableListOf<AnyRow>() // 데이터 로딩을 위한 초기 페이지 경로를 설정합니다. var pagePath = path do { // 현재 페이지 경로에서 데이터를 로드합니다. val row = load(pagePath) // 로드된 데이터를 행으로서 리스트에 추가합니다. rows.add(row) // 사용 가능한 경우 다음 페이지를 위한 토큰을 가져옵니다. val next = row.getValueOrNull<String>("nextPageToken") // 새 토큰을 포함하여 다음 반복을 위한 페이지 경로를 업데이트합니다. pagePath = path + "&pageToken=" + next // 다음 페이지가 없거나 최대 페이지 수에 도달할 때까지 페이지 로딩을 계속합니다. } while (next != null && rows.size < maxPages) // 로드된 모든 행을 DataFrame으로 결합하여 반환합니다. return rows.concat() }이전에 정의한
load()함수를 사용하여 새 코드 셀에서 데이터를 가져오고 DataFrame을 생성합니다. 이 예제에서는 Kotlin과 관련된 비디오 데이터를 가져오며, 페이지당 최대 50개의 결과로 최대 5페이지까지 가져옵니다. 결과는df변수에 저장됩니다:kotlinval df = load("search?q=kotlin&maxResults=50&part=snippet", 5) df마지막으로 DataFrame에서 항목(items)을 추출하고 결합합니다:
kotlinval items = df.items.concat() items
데이터 정제 및 가공
데이터 정제(Cleaning) 및 가공(Refining)은 분석을 위해 데이터셋을 준비하는 중요한 단계입니다. Kotlin DataFrame 라이브러리는 이러한 작업을 위한 강력한 기능을 제공합니다. move, concat, select, parse, join과 같은 메서드들은 데이터를 정리하고 변환하는 데 유용합니다.
이미 YouTube Data API를 사용하여 가져온 데이터를 예로 들어보겠습니다. 목표는 심층 분석을 준비하기 위해 데이터셋을 정제하고 재구성하는 것입니다:
먼저 데이터를 재구성하고 정제하는 것으로 시작할 수 있습니다. 여기에는 특정 컬럼을 새 헤더 아래로 이동시키고 명확성을 위해 불필요한 컬럼을 제거하는 작업이 포함됩니다:
kotlinval videos = items.dropNulls { id.videoId } .select { id.videoId named "id" and snippet } .distinct() videos정제된 데이터에서 ID를 청크(chunk)로 나누고 해당 비디오 통계를 로드합니다. 데이터를 작은 배치로 나누고 추가 세부 정보를 가져오는 작업이 포함됩니다:
kotlinval statPages = clean.id.chunked(50).map { val ids = it.joinToString("%2C") load("videos?part=statistics&id=$ids") } statPages가져온 통계를 결합하고 관련 컬럼을 선택합니다:
kotlinval stats = statPages.items.concat().select { id and statistics.all() }.parse() stats기존의 정제된 데이터와 새로 가져온 통계를 조인(Join)합니다. 이를 통해 두 데이터셋을 하나의 종합적인 DataFrame으로 병합합니다:
kotlinval joined = clean.join(stats) joined
이 예제는 Kotlin DataFrame의 다양한 함수를 사용하여 데이터셋을 정제, 재구성 및 향상시키는 방법을 보여줍니다. 각 단계는 데이터를 가공하여 심층 분석에 더 적합하게 만들도록 설계되었습니다.
Kotlin Notebook에서 데이터 분석
Kotlin DataFrame 라이브러리의 함수를 사용하여 성공적으로 데이터를 가져오고 데이터를 정제 및 가공했다면, 다음 단계는 이 준비된 데이터셋을 분석하여 의미 있는 인사이트를 추출하는 것입니다.
데이터 분류를 위한 groupBy, 요약 통계를 위한 sum 및 maxBy, 데이터 정렬을 위한 sortBy와 같은 메서드들이 특히 유용합니다. 이러한 도구들을 사용하면 복잡한 데이터 분석 작업을 효율적으로 수행할 수 있습니다.
groupBy를 사용하여 비디오를 채널별로 분류하고, sum을 사용하여 카테고리별 총 조회수를 계산하며, maxBy를 사용하여 각 그룹에서 최신 또는 가장 많이 본 비디오를 찾는 예제를 살펴보겠습니다:
특정 컬럼에 대한 참조를 설정하여 접근을 간소화합니다:
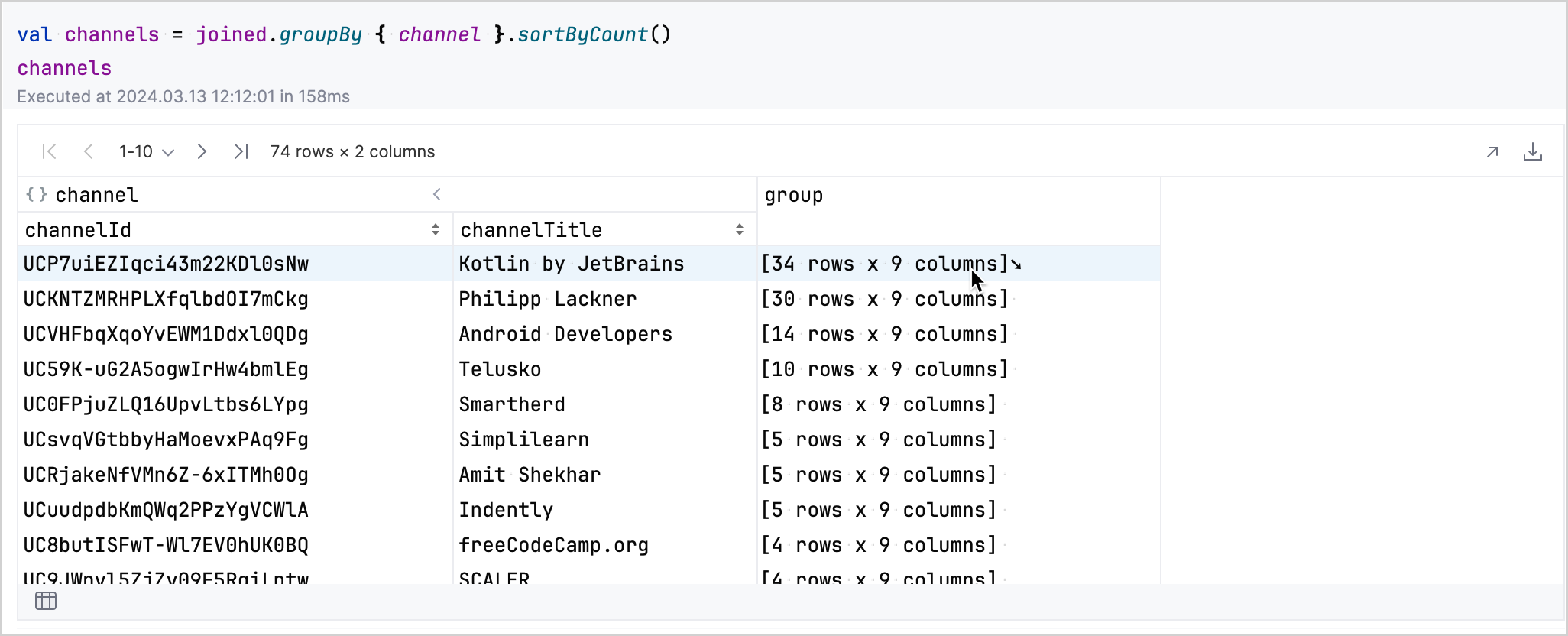
kotlinval view by column<Int>()groupBy메서드를 사용하여 데이터를channel컬럼별로 그룹화하고 정렬합니다.kotlinval channels = joined.groupBy { channel }.sortByCount()
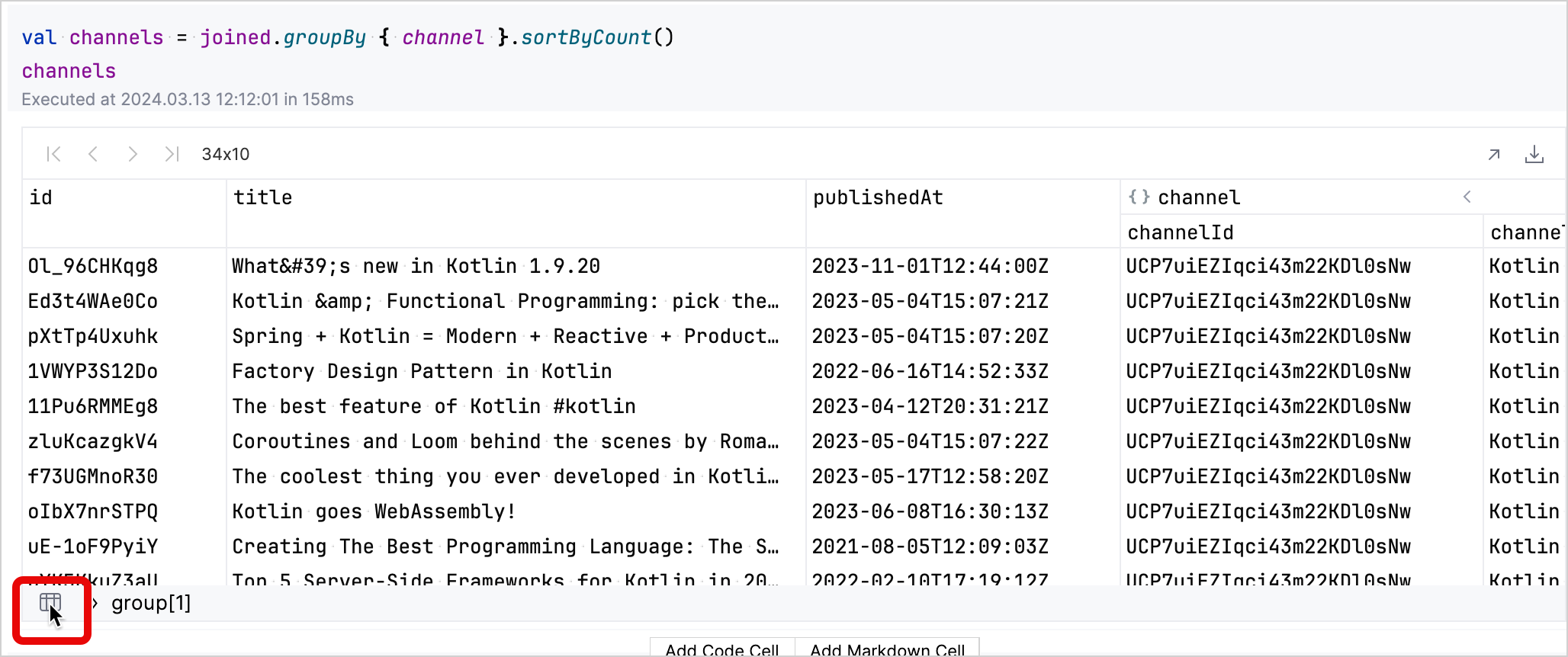
결과 테이블에서 데이터를 대화형으로 탐색할 수 있습니다. 채널에 해당하는 행의 group 필드를 클릭하면 해당 행이 확장되어 해당 채널 비디오에 대한 자세한 내용이 표시됩니다.
왼쪽 하단의 테이블 아이콘을 클릭하면 그룹화된 데이터셋으로 돌아갈 수 있습니다.
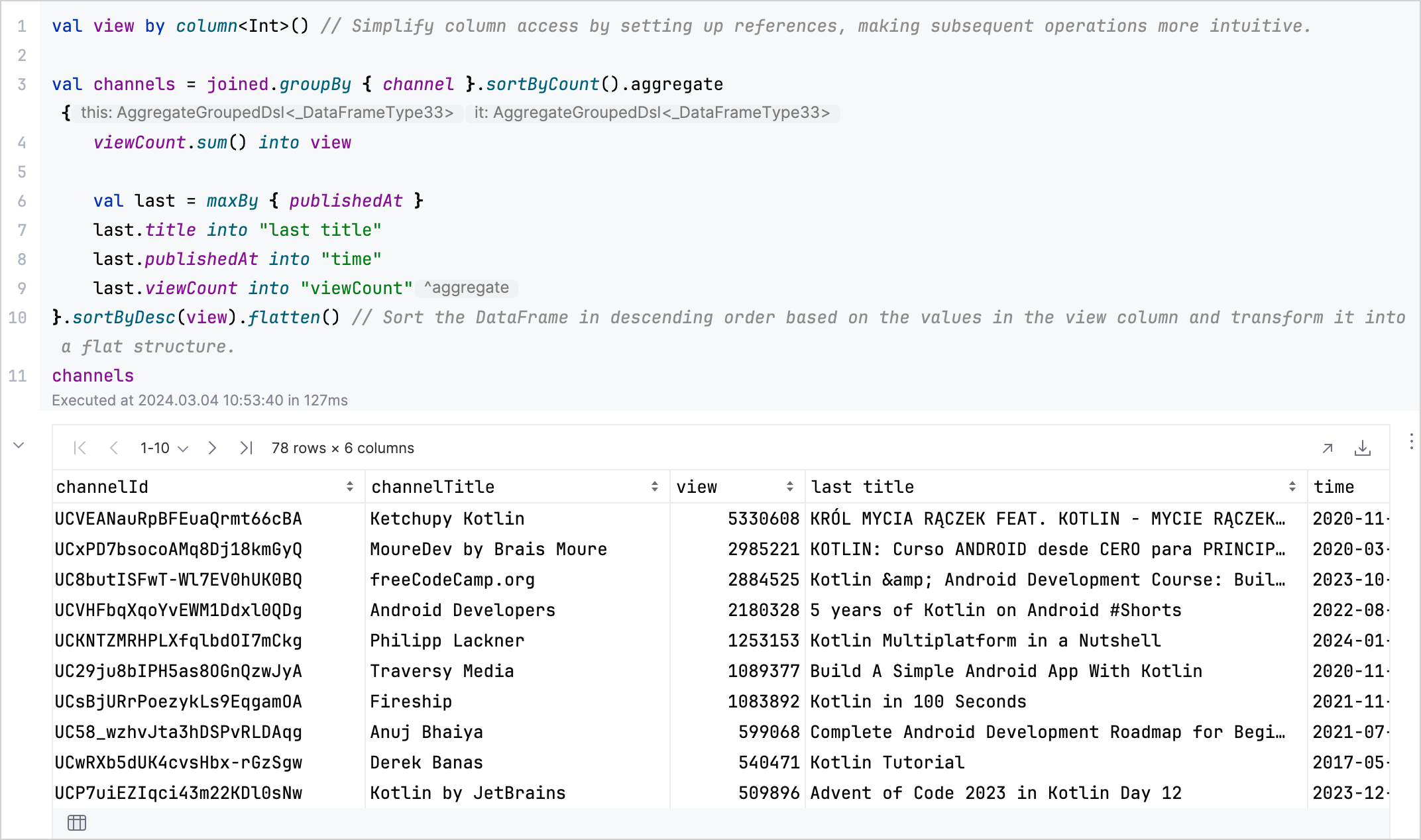
aggregate,sum,maxBy,flatten을 사용하여 각 채널의 총 조회수와 최신 또는 가장 많이 본 비디오의 세부 정보를 요약하는 DataFrame을 생성합니다:kotlinval aggregated = channels.aggregate { viewCount.sum() into view val last = maxBy { publishedAt } last.title into "last title" last.publishedAt into "time" last.viewCount into "viewCount" // DataFrame을 조회수 기준 내림차순으로 정렬하고 평탄한(flat) 구조로 변환합니다. }.sortByDesc(view).flatten() aggregated
분석 결과:
더 고급 기술에 대해서는 Kotlin DataFrame 문서를 참조하세요.
다음 단계
- Kandy 라이브러리를 사용한 데이터 시각화 탐색
- Kandy를 사용한 Kotlin Notebook의 데이터 시각화에서 데이터 시각화에 대한 추가 정보 확인
- Kotlin의 데이터 과학 및 분석을 위한 도구와 리소스에 대한 광범위한 개요는 데이터 분석을 위한 Kotlin 및 Java 라이브러리를 참조하세요.