파일에서 데이터 가져오기
Kotlin Notebook은 Kotlin DataFrame 라이브러리와 결합하여 비정형 및 정형 데이터를 모두 다룰 수 있게 해줍니다. 이러한 조합은 TXT 파일에서 찾을 수 있는 데이터와 같은 비정형 데이터를 정형 데이터셋으로 변환할 수 있는 유연성을 제공합니다.
데이터 변환을 위해 .add(), .split(), .convert(), .parse()와 같은 메서드를 사용할 수 있습니다. 또한, 이 툴셋을 사용하면 CSV, JSON, XLS, Parquet, Apache Arrow를 포함한 다양한 정형 파일 형식에서 데이터를 가져오고 조작할 수 있습니다. 지원되는 모든 형식은 DataFrame 문서를 참조하세요.
이 가이드에서는 여러 예제를 통해 데이터를 가져오고, 정제하고, 처리하는 방법을 배울 수 있습니다.
시작하기 전에
Kotlin Notebook은 IntelliJ IDEA에 기본적으로 내장되어 활성화되어 있는 Kotlin Notebook 플러그인에 의존합니다.
Kotlin Notebook 기능을 사용할 수 없는 경우 플러그인이 활성화되어 있는지 확인하세요. 자세한 내용은 환경 설정을 참조하세요.
이 튜토리얼을 따라 하려면 다음을 수행하세요:
새 Kotlin Notebook을 생성합니다.
Kotlin DataFrame을 임포트합니다:
kotlin%use dataframe
노트북에서 DataFrame 라이브러리와 해당 API를 사용할 수 있도록 다른 코드 셀을 실행하기 전에
%use dataframe줄이 포함된 코드 셀을 먼저 실행하세요.
데이터 가져오기
파일의 데이터를 Kotlin Notebook으로 가져오려면 DataFrame.read() 함수를 사용하세요:
val movies = DataFrame.read("movies.csv")DataFrame.read() 함수는 파일 확장자와 내용을 기반으로 입력 형식을 감지합니다.
또한 DataFrame 라이브러리가 입력 데이터를 읽는 방식을 제어하기 위해 추가 인수를 전달할 수도 있습니다. 예를 들어, 다음 코드는 CSV 파일에 대해 커스텀 구분자(;)를 지정합니다:
val movies = DataFrame.read("movies.csv", delimiter = ';')추가적인 파일 형식과 다양한 읽기 함수에 대한 포괄적인 개요는 Kotlin DataFrame 라이브러리 문서를 참조하세요.
데이터 표시하기
노트북에 데이터를 가져온 후에는 이를 표시할 수 있습니다. 가장 쉬운 방법은 데이터를 변수에 저장한 다음 해당 변수를 반환하는 것입니다:
val jsonDf = DataFrame.read("jsonFile.json")
jsonDf이 코드는 파일의 데이터를 대화형 테이블로 표시합니다:
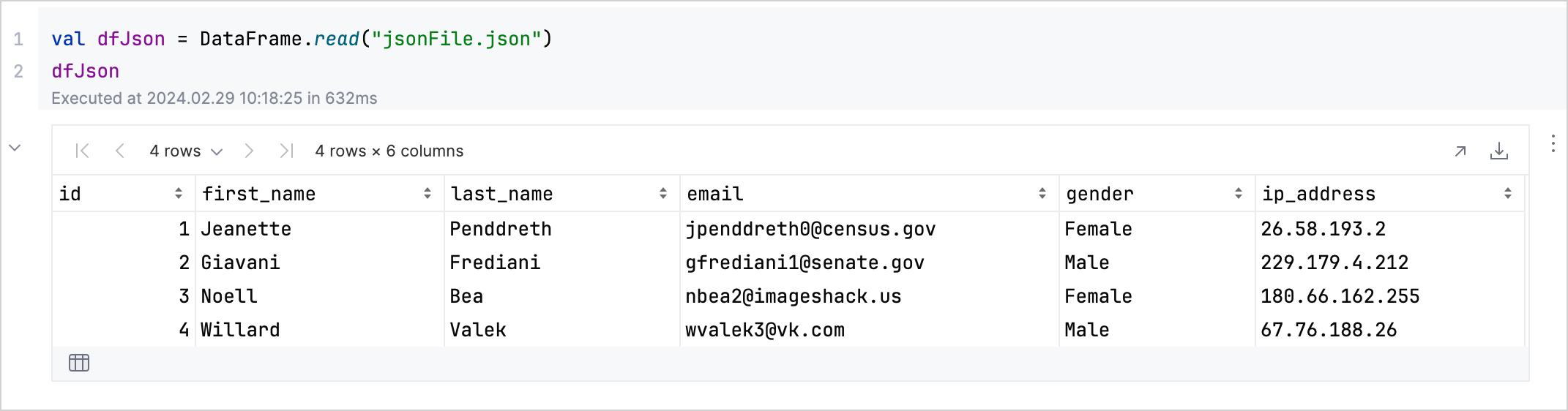
이 뷰를 사용하여 값을 검사하고, 컬럼 이름을 확인하며, 데이터셋의 상태를 쉽게 이해할 수 있습니다.
데이터 구조 검사하기
데이터의 구조나 스키마(schema)에 대한 통찰력을 얻으려면 DataFrame 변수에 .schema() 함수를 사용하세요.
예를 들어, jsonDf.schema()를 실행하여 JSON 데이터셋에 있는 각 컬럼의 타입을 나열합니다:
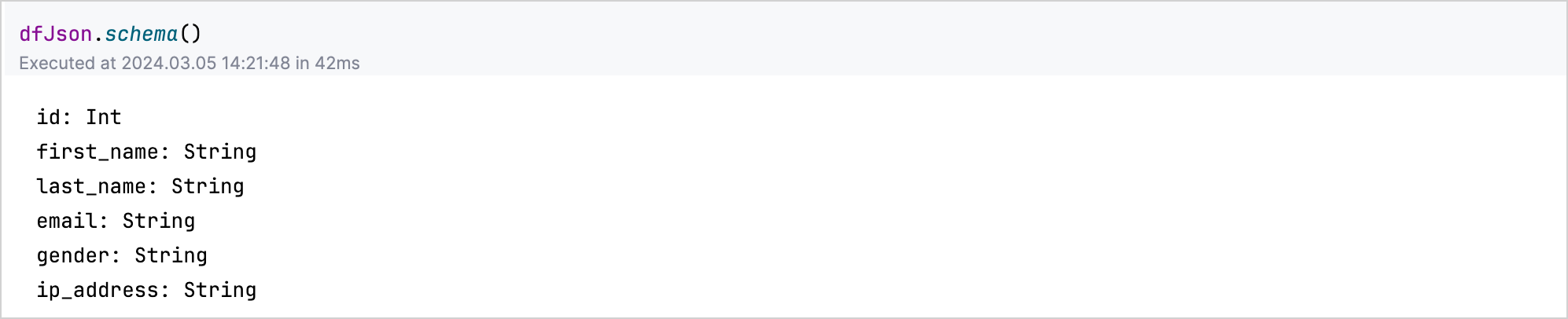
Kotlin Notebook에서는 자동 완성 기능도 사용할 수 있습니다. 이 기능을 사용하면 DataFrame의 속성에 빠르게 액세스하고 조작할 수 있습니다. 데이터를 로드한 후 DataFrame 변수 뒤에 점(.)을 입력하면 사용 가능한 컬럼과 해당 타입의 목록을 볼 수 있습니다.
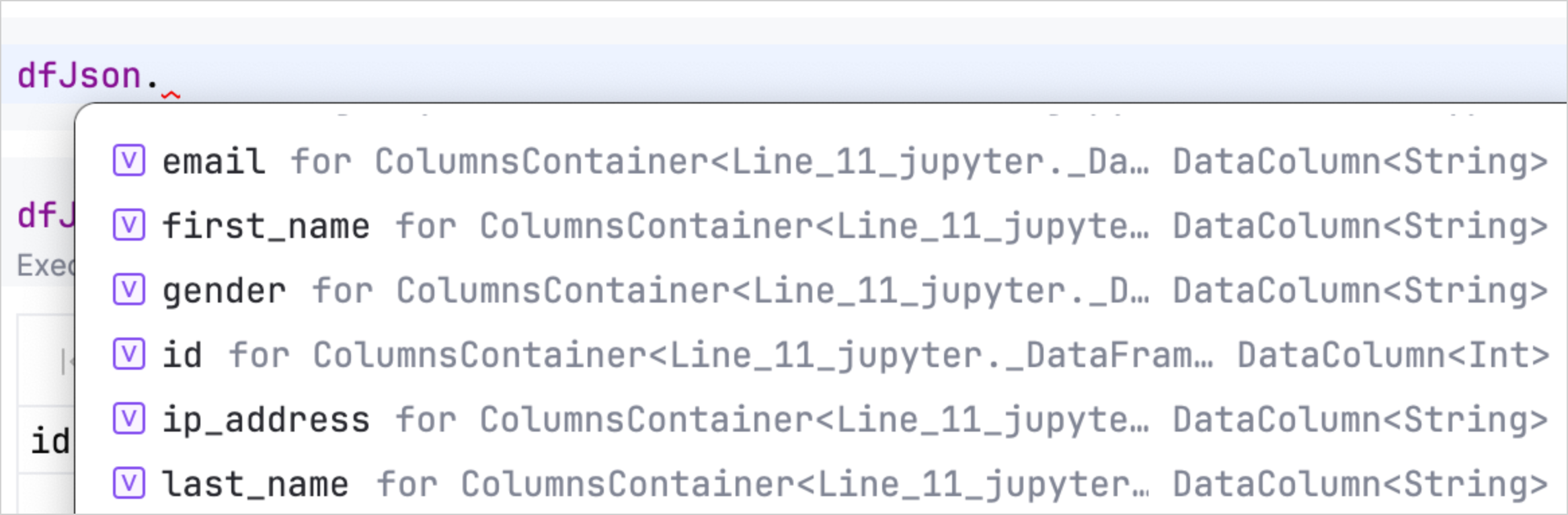
데이터 정제하기
Kotlin DataFrame은 데이터셋 정제를 위한 다양한 연산을 제공합니다. 예를 들어 그룹화(grouping), 필터링(filtering), 업데이트(updating), 또는 새 컬럼 추가(adding new columns)가 있습니다. 이러한 함수는 데이터 분석에 필수적이며, 데이터를 효과적으로 구성, 정리 및 변환할 수 있게 해줍니다.
예를 들어, movies.csv 데이터셋을 살펴보겠습니다. 이 데이터셋은 영화 제목과 개봉 연도를 동일한 셀에 저장하고 있습니다. 목표는 더 쉬운 분석을 위해 이 데이터셋을 정제하는 것입니다:
데이터 로드
.read()함수를 사용하여 파일을DataFrame으로 로드합니다:kotlinval movies = DataFrame.read("movies.csv")컬럼 추가
title컬럼에서 개봉 연도를 추출하기 위해 새year컬럼을 추가합니다:kotlinval moviesWithYear = movies .add("year") { "\\d{4}".toRegex() .findAll(title) .lastOrNull() ?.value ?.toInt() ?: -1 } moviesWithYear값 업데이트
영화 제목에서 개봉 연도를 제거하기 위해
title컬럼을 업데이트합니다:kotlinval moviesTitle = moviesWithYear .update("title") { "\\s*\\(\\d{4}\\)\\s*$".toRegex().replace(title, "") } moviesTitle이 코드는 영화 제목을 한 컬럼에 유지하고 개봉 연도를 다른 컬럼으로 이동시킵니다.
행 필터링
특정 데이터에 집중하려면
.filter()함수를 사용하세요. 예를 들어, 1996년 이후에 개봉된 영화만 유지하려면 다음을 실행합니다:kotlinval newMovies = moviesTitle.filter { year >= 1996 } newMovies컬럼 제거
필요하지 않은 컬럼을 제거하려면
.remove()함수를 사용하세요:kotlinval refinedMovies = newMovies.remove { movieID } refinedMovies
비교를 위해, 정제 전의 데이터셋은 다음과 같습니다:
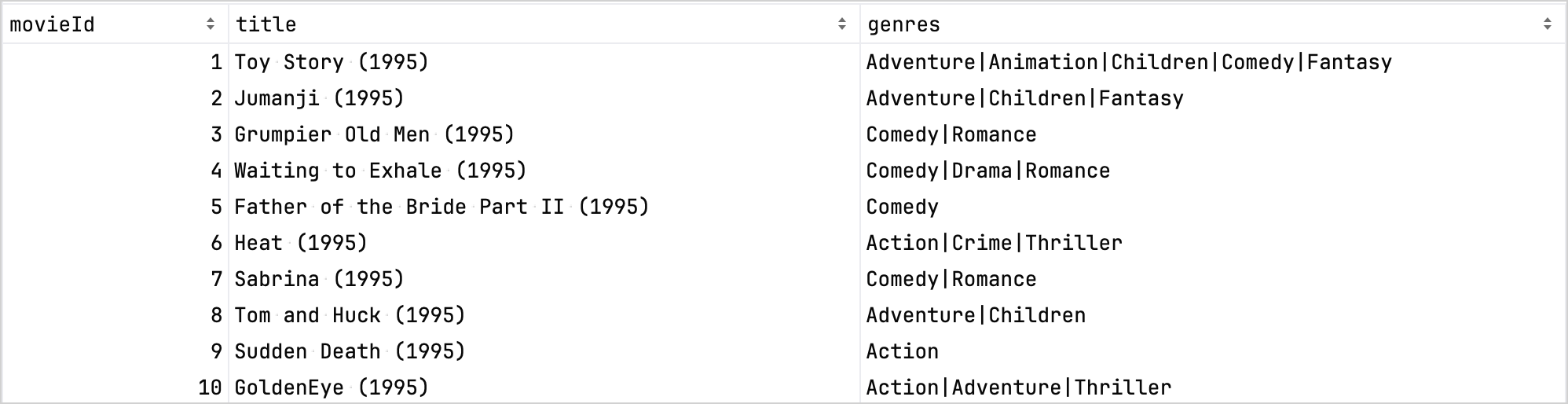
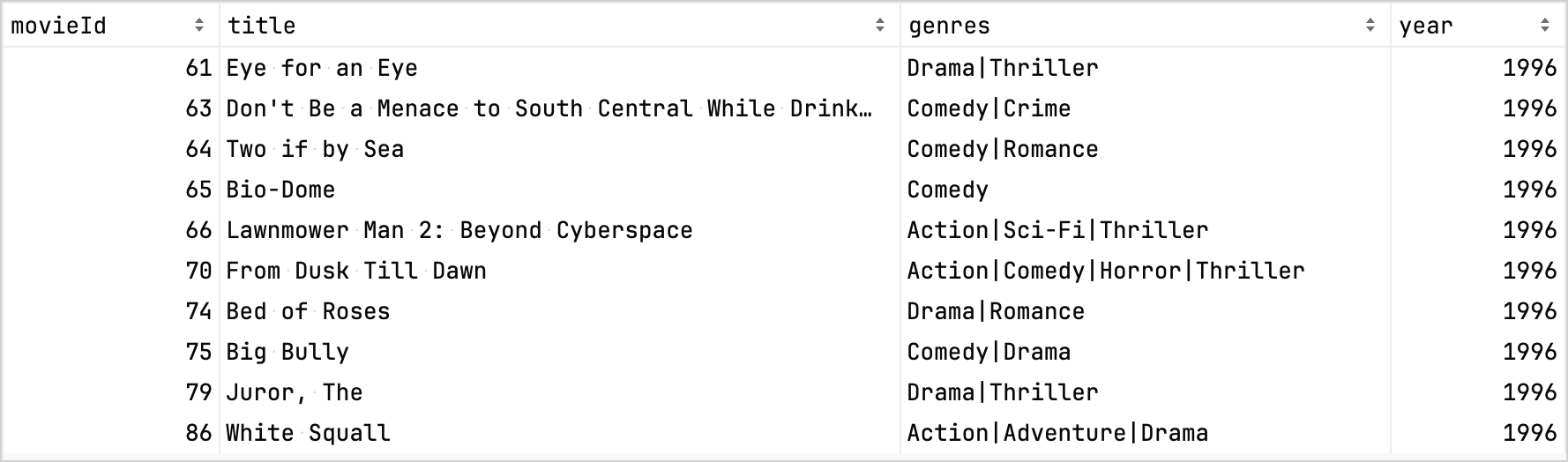
정제 후의 데이터셋입니다:
추가적인 사용 사례와 자세한 예제는 Kotlin Dataframe 예제를 참조하세요.
데이터 내보내기
Kotlin Notebook에서 데이터를 정제한 후, 처리된 데이터를 쉽게 내보낼 수 있습니다.
이 목적으로 다양한 .write() 함수를 활용할 수 있습니다. CSV, JSON, XLS, XLSX, Apache Arrow, 그리고 HTML 테이블을 포함한 여러 형식으로 저장을 지원합니다. 지원되는 모든 형식은 DataFrame 문서를 참조하세요. 이는 분석 결과를 공유하거나, 보고서를 작성하거나, 추가 분석을 위해 데이터를 사용할 수 있게 만드는 데 특히 유용할 수 있습니다.
예를 들어, 결과를 다음과 같이 저장해 보겠습니다:
.writeJson()함수를 사용한 JSON 파일:kotlinrefinedMovies.writeJson("movies.json").writeCsv()함수를 사용한 CSV 파일:kotlinrefinedMovies.writeCsv("movies.csv").writeArrowIPC()및.writeArrowFeather()함수를 사용한 Apache Arrow 파일:kotlinrefinedMovies.writeArrowIPC("movies.arrow") refinedMovies.writeArrowFeather("movies.feather")
또한 .toStandaloneHTML() 함수를 사용하여 브라우저에서 독립형 HTML 테이블을 열 수도 있습니다:
refinedMoviesDf
.toStandaloneHTML(DisplayConfiguration(rowsLimit = null))
.openInBrowser()다음 단계
- Kandy 라이브러리를 사용하여 데이터 시각화 살펴보기
- Kandy를 사용한 Kotlin Notebook의 데이터 시각화에서 데이터 시각화에 대한 추가 정보 찾기
- Kotlin에서의 데이터 과학 및 분석을 위한 도구와 리소스에 대한 광범위한 개요는 데이터 분석을 위한 Kotlin 및 Java 라이브러리를 참조하세요.