코루틴과 채널 − 튜토리얼
이 튜토리얼에서는 IntelliJ IDEA에서 코루틴을 사용하여 기본 스레드(underlying thread)를 차단하거나 콜백을 사용하지 않고 네트워크 요청을 수행하는 방법을 배웁니다.
코루틴에 대한 사전 지식은 필요하지 않지만, 기본적인 Kotlin 문법에는 익숙해야 합니다.
이 튜토리얼에서 배울 내용:
- 네트워크 요청을 수행하기 위해 일시 중단 함수(suspending functions)를 사용하는 이유와 방법.
- 코루틴을 사용하여 요청을 동시에(concurrently) 보내는 방법.
- 채널(channels)을 사용하여 서로 다른 코루틴 간에 정보를 공유하는 방법.
네트워크 요청을 위해 Retrofit 라이브러리를 사용하지만, 이 튜토리얼에서 보여주는 방식은 코루틴을 지원하는 다른 라이브러리에서도 유사하게 작동합니다.
모든 작업의 솔루션은 프로젝트 저장소의
solutions브랜치에서 찾을 수 있습니다.
시작하기 전에
최신 버전의 IntelliJ IDEA를 다운로드하여 설치합니다.
환영 화면에서 Get from VCS를 선택하거나 File | New | Project from Version Control을 선택하여 프로젝트 템플릿을 클론합니다.
커맨드 라인에서 클론할 수도 있습니다:
Bashgit clone https://github.com/kotlin-hands-on/intro-coroutines
GitHub 개발자 토큰 생성하기
프로젝트에서 GitHub API를 사용하게 됩니다. 액세스 권한을 얻으려면 GitHub 계정 이름과 비밀번호 또는 토큰을 제공해야 합니다. 2단계 인증(two-factor authentication)을 사용 중이라면 토큰만으로 충분합니다.
GitHub 계정에서 GitHub API를 사용하기 위한 새로운 토큰을 생성하세요:
토큰의 이름을 지정합니다 (예:
coroutines-tutorial):
스코프(scopes)는 선택하지 마세요. 페이지 하단의 Generate token을 클릭합니다.
생성된 토큰을 복사합니다.
코드 실행하기
이 프로그램은 지정된 조직(기본값은 "kotlin") 아래의 모든 저장소에 대한 기여자(contributors) 목록을 불러옵니다. 나중에 기여 횟수에 따라 사용자를 정렬하는 로직을 추가할 것입니다.
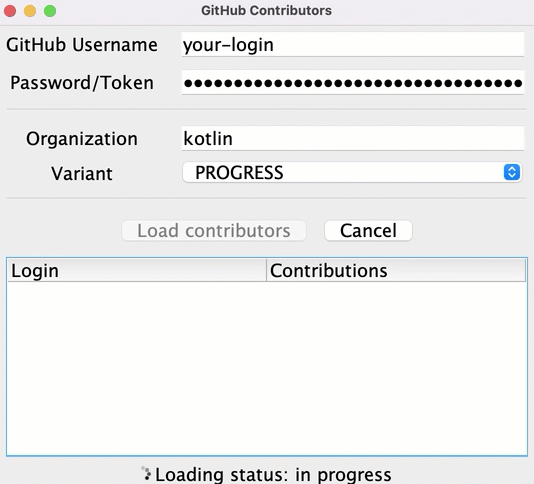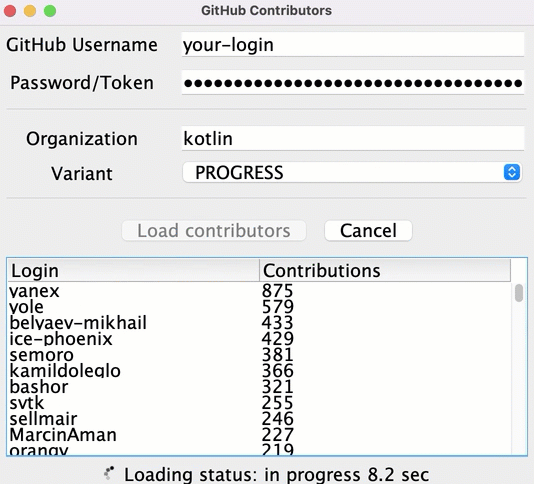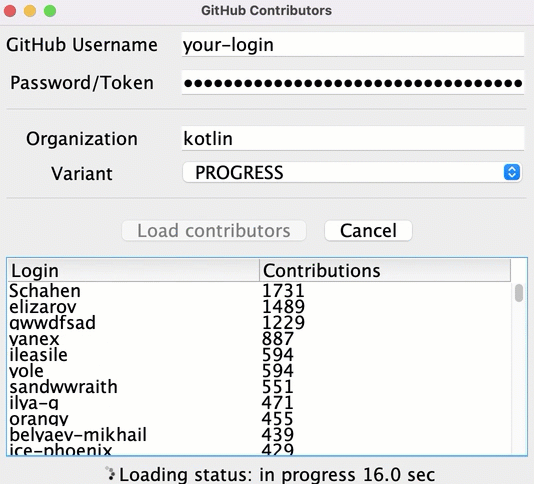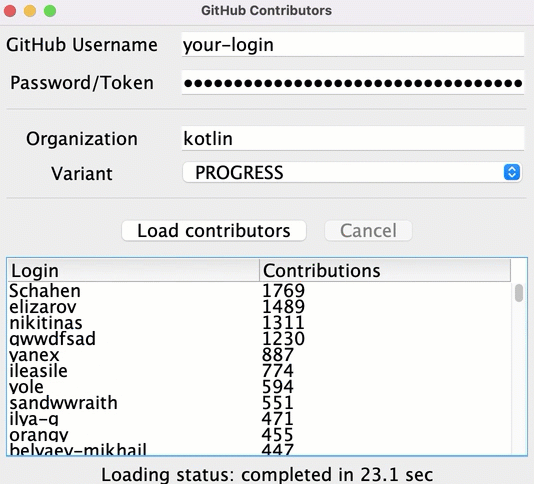
src/contributors/main.kt파일을 열고main()함수를 실행합니다. 다음과 같은 창이 나타납니다: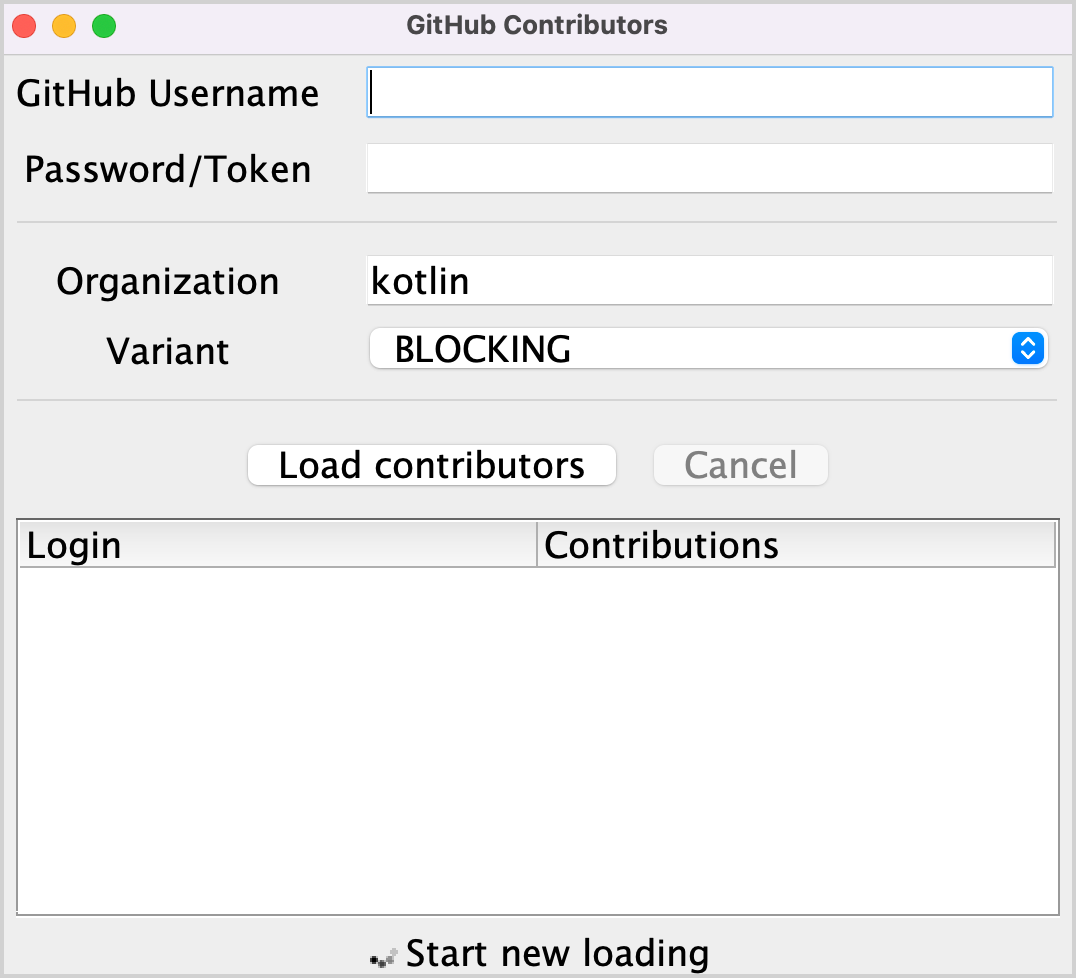
글꼴이 너무 작다면
main()함수의setDefaultFontSize(18f)값을 변경하여 조정하세요.해당 필드에 GitHub 사용자 이름과 토큰(또는 비밀번호)을 입력합니다.
Variant 드롭다운 메뉴에서 BLOCKING 옵션이 선택되어 있는지 확인합니다.
_Load contributors_를 클릭합니다. UI가 잠시 멈췄다가 기여자 목록이 표시될 것입니다.
프로그램 출력을 열어 데이터가 로드되었는지 확인합니다. 각 요청이 성공할 때마다 기여자 목록이 로그에 기록됩니다.
이 로직을 구현하는 방법은 여러 가지가 있습니다: 블로킹 요청(blocking requests) 또는 콜백(callbacks)을 사용하는 방식입니다. 이러한 해결책들을 코루틴(coroutines)을 사용하는 방식과 비교해 보고, 채널(channels)을 사용하여 서로 다른 코루틴 간에 정보를 공유하는 방법을 알아보겠습니다.
블로킹 요청 (Blocking requests)
Retrofit 라이브러리를 사용하여 GitHub에 HTTP 요청을 보낼 것입니다. 이 라이브러리를 통해 특정 조직의 저장소 목록과 각 저장소의 기여자 목록을 요청할 수 있습니다:
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
fun getOrgReposCall(
@Path("org") org: String
): Call<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Call<List<User>>
}이 API는 loadContributorsBlocking() 함수에서 지정된 조직의 기여자 목록을 가져오는 데 사용됩니다.
src/tasks/Request1Blocking.kt를 열어 구현 내용을 확인하세요:kotlinfun loadContributorsBlocking( service: GitHubService, req: RequestData ): List<User> { val repos = service .getOrgReposCall(req.org) // #1 .execute() // #2 .also { logRepos(req, it) } // #3 .body() ?: emptyList() // #4 return repos.flatMap { repo -> service .getRepoContributorsCall(req.org, repo.name) // #1 .execute() // #2 .also { logUsers(repo, it) } // #3 .bodyList() // #4 }.aggregate() }- 먼저 지정된 조직 아래의 저장소 목록을 가져와
repos리스트에 저장합니다. 그다음 각 저장소에 대해 기여자 목록을 요청하고, 모든 리스트를 하나의 최종 기여자 리스트로 병합합니다. getOrgReposCall()과getRepoContributorsCall()은 모두*Call클래스의 인스턴스를 반환합니다(#1). 이 시점에서는 요청이 전송되지 않습니다.- 그 후
*Call.execute()를 호출하여 요청을 수행합니다(#2).execute()는 기본 스레드를 차단하는 동기 호출입니다. - 응답을 받으면
logRepos()와logUsers()함수를 호출하여 결과를 로그에 남깁니다(#3). HTTP 응답에 에러가 포함되어 있으면 여기서 로그가 기록됩니다. - 마지막으로 필요한 데이터가 포함된 응답 바디를 가져옵니다. 이 튜토리얼에서는 에러가 발생할 경우 빈 리스트를 결과로 사용하고 해당 에러를 로그에 남깁니다(
#4).
- 먼저 지정된 조직 아래의 저장소 목록을 가져와
.body() ?: emptyList()의 반복을 피하기 위해bodyList()확장 함수가 선언되어 있습니다:kotlinfun <T> Response<List<T>>.bodyList(): List<T> { return body() ?: emptyList() }프로그램을 다시 실행하고 IntelliJ IDEA의 시스템 출력을 확인하세요. 다음과 같은 내용이 표시될 것입니다:
text1770 [AWT-EventQueue-0] INFO Contributors - kotlin: loaded 40 repos 2025 [AWT-EventQueue-0] INFO Contributors - kotlin-examples: loaded 23 contributors 2229 [AWT-EventQueue-0] INFO Contributors - kotlin-koans: loaded 45 contributors ...- 각 줄의 첫 번째 항목은 프로그램 시작 후 경과된 시간(밀리초)이며, 그다음 대괄호 안에는 스레드 이름이 표시됩니다. 어느 스레드에서 로딩 요청이 호출되는지 확인할 수 있습니다.
- 마지막 항목은 실제 메시지로, 로드된 저장소 또는 기여자의 수입니다.
이 로그 출력은 모든 결과가 메인 스레드에서 기록되었음을 보여줍니다. BLOCKING 옵션으로 코드를 실행하면 로딩이 완료될 때까지 창이 멈추고 입력에 반응하지 않습니다. 모든 요청은
loadContributorsBlocking()이 호출된 스레드와 동일한 스레드, 즉 메인 UI 스레드(Swing의 경우 AWT 이벤트 파견 스레드)에서 실행됩니다. 이 메인 스레드가 차단되기 때문에 UI가 얼어붙는 것입니다:
기여자 목록이 로드된 후 결과가 업데이트됩니다.
src/contributors/Contributors.kt에서 기여자를 로드하는 방식을 선택하는loadContributors()함수를 찾아loadContributorsBlocking()이 어떻게 호출되는지 확인하세요:kotlinwhen (getSelectedVariant()) { BLOCKING -> { // UI 스레드를 차단함 val users = loadContributorsBlocking(service, req) updateResults(users, startTime) } }updateResults()호출은loadContributorsBlocking()호출 바로 다음에 옵니다.updateResults()는 UI를 업데이트하므로 반드시 UI 스레드에서 호출되어야 합니다.loadContributorsBlocking()역시 UI 스레드에서 호출되므로 UI 스레드가 차단되고 UI가 멈추게 됩니다.
과제 1
첫 번째 과제는 도메인에 익숙해지는 것입니다. 현재 각 기여자의 이름은 참여한 프로젝트마다 한 번씩 반복되고 있습니다. 각 기여자가 한 번만 추가되도록 사용자 정보를 결합하는 aggregate() 함수를 구현하세요. User.contributions 속성에는 해당 사용자가 모든 프로젝트에서 기여한 총 횟수가 포함되어야 합니다. 결과 리스트는 기여 횟수에 따라 내림차순으로 정렬되어야 합니다.
src/tasks/Aggregation.kt를 열고 List<User>.aggregate() 함수를 구현하세요. 사용자는 총 기여 횟수에 따라 정렬되어야 합니다.
해당 테스트 파일인 test/tasks/AggregationKtTest.kt에서 예상 결과의 예를 확인할 수 있습니다.
IntelliJ IDEA 단축키
Ctrl+Shift+T/⇧ ⌘ T를 사용하여 소스 코드와 테스트 클래스 사이를 자동으로 이동할 수 있습니다.
이 과제를 구현한 후 "kotlin" 조직의 결과 리스트는 다음과 유사해야 합니다:
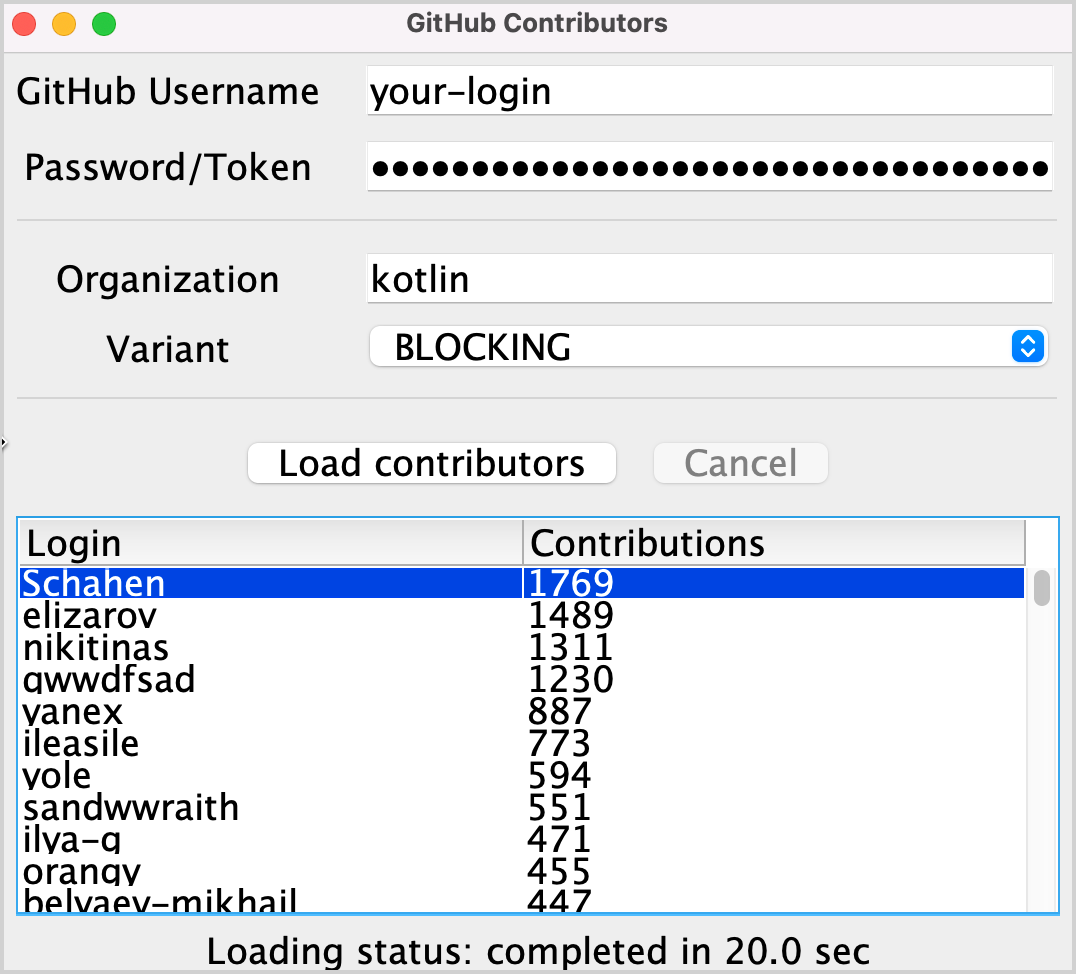
과제 1 솔루션
로그인을 기준으로 사용자를 그룹화하려면
groupBy()를 사용하세요. 이는 로그인에서 해당 로그인을 가진 사용자가 여러 저장소에서 나타난 모든 항목으로의 맵을 반환합니다.각 맵 항목에 대해 사용자별 총 기여 횟수를 계산하고, 지정된 이름과 총 기여 횟수로
User클래스의 새 인스턴스를 생성합니다.결과 리스트를 내림차순으로 정렬합니다:
kotlinfun List<User>.aggregate(): List<User> = groupBy { it.login } .map { (login, group) -> User(login, group.sumOf { it.contributions }) } .sortedByDescending { it.contributions }
대안으로 groupBy() 대신 groupingBy() 함수를 사용할 수도 있습니다.
콜백 (Callbacks)
이전 해결책은 작동하지만 스레드를 차단하여 UI를 멈추게 합니다. 이를 피하기 위한 전통적인 접근 방식은 _콜백_을 사용하는 것입니다.
작업이 완료된 직후에 호출되어야 하는 코드를 직접 호출하는 대신, 별도의 콜백(주로 람다)으로 추출하여 나중에 호출될 수 있도록 호출자에게 전달할 수 있습니다.
UI를 반응형으로 유지하려면 전체 계산을 별도의 스레드로 옮기거나, 블로킹 호출 대신 콜백을 사용하는 Retrofit API로 전환할 수 있습니다.
백그라운드 스레드 사용하기
src/tasks/Request2Background.kt를 열어 구현 내용을 확인하세요. 먼저 전체 계산이 다른 스레드로 이동됩니다.thread()함수는 새 스레드를 시작합니다:kotlinthread { loadContributorsBlocking(service, req) }이제 모든 로딩이 별도의 스레드로 이동되었으므로 메인 스레드는 자유로워져 다른 작업을 수행할 수 있습니다:

loadContributorsBackground()함수의 시그니처가 변경됩니다. 로딩이 모두 완료된 후 호출할updateResults()콜백을 마지막 인자로 받습니다:kotlinfun loadContributorsBackground( service: GitHubService, req: RequestData, updateResults: (List<User>) -> Unit )이제
loadContributorsBackground()가 호출될 때updateResults()호출은 이전처럼 즉시 실행되지 않고 콜백 안에서 이루어집니다:kotlinloadContributorsBackground(service, req) { users -> SwingUtilities.invokeLater { updateResults(users, startTime) } }SwingUtilities.invokeLater를 호출함으로써 결과를 업데이트하는updateResults()호출이 메인 UI 스레드(AWT 이벤트 파견 스레드)에서 실행되도록 보장합니다.
하지만 BACKGROUND 옵션을 통해 기여자를 로드하려고 하면 리스트가 업데이트되기는 하지만 아무것도 변하지 않는 것을 볼 수 있습니다.
과제 2
src/tasks/Request2Background.kt의 loadContributorsBackground() 함수를 수정하여 결과 리스트가 UI에 표시되도록 하세요.
과제 2 솔루션
기여자를 로드하려고 하면 로그에는 기여자가 로드된 것으로 나타나지만 결과가 표시되지 않습니다. 이를 수정하려면 결과 사용자 리스트에 대해 updateResults()를 호출해야 합니다:
thread {
updateResults(loadContributorsBlocking(service, req))
}콜백으로 전달된 로직을 명시적으로 호출해야 합니다. 그렇지 않으면 아무 일도 일어나지 않습니다.
Retrofit 콜백 API 사용하기
이전 해결책에서는 전체 로딩 로직을 백그라운드 스레드로 옮겼지만, 여전히 리소스 활용 측면에서 최선은 아닙니다. 모든 로딩 요청이 순차적으로 처리되며 로딩 결과를 기다리는 동안 스레드가 차단되는데, 이 시간 동안 스레드는 다른 작업을 수행할 수 있었습니다. 특히 스레드는 전체 결과를 더 빨리 받기 위해 다른 요청 로딩을 시작할 수도 있었습니다.
따라서 각 저장소에 대한 데이터 처리는 로딩과 결과 응답 처리라는 두 부분으로 나뉘어야 합니다. 두 번째 처리(processing) 부분은 콜백으로 추출되어야 합니다.
그러면 각 저장소에 대한 로딩은 이전 저장소의 결과를 받기 전(그리고 해당 콜백이 호출되기 전)에 시작될 수 있습니다:

Retrofit 콜백 API가 이를 도와줄 수 있습니다. Call.enqueue() 함수는 HTTP 요청을 시작하고 콜백을 인자로 받습니다. 이 콜백에서 각 요청 후에 수행할 작업을 지정해야 합니다.
src/tasks/Request3Callbacks.kt를 열고 이 API를 사용하는 loadContributorsCallbacks()의 구현을 확인하세요:
fun loadContributorsCallbacks(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
) {
service.getOrgReposCall(req.org).onResponse { responseRepos -> // #1
logRepos(req, responseRepos)
val repos = responseRepos.bodyList()
val allUsers = mutableListOf<User>()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers -> // #2
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
}
}
}
// TODO: 왜 이 코드가 작동하지 않을까요? 어떻게 수정해야 할까요?
updateResults(allUsers.aggregate())
}- 편의를 위해 이 코드 조각은 같은 파일에 선언된
onResponse()확장 함수를 사용합니다. 이 함수는 객체 표현식 대신 람다를 인자로 받습니다. - 응답 처리 로직은 콜백으로 추출되었습니다. 해당 람다는
#1과#2라인에서 시작됩니다.
하지만 제공된 해결책은 작동하지 않습니다. 프로그램을 실행하고 CALLBACKS 옵션을 선택하여 기여자를 로드하면 아무것도 표시되지 않습니다. 하지만 Request3CallbacksKtTest의 테스트는 즉시 성공 결과를 반환합니다.
주어진 코드가 왜 예상대로 작동하지 않는지 생각해 보고 직접 수정해 보거나 아래의 솔루션을 확인하세요.
과제 3 (선택 사항)
src/tasks/Request3Callbacks.kt 파일의 코드를 다시 작성하여 로드된 기여자 리스트가 표시되도록 하세요.
과제 3에 대한 첫 번째 시도
현재 해결책에서는 많은 요청이 동시에 시작되어 전체 로딩 시간이 단축됩니다. 하지만 결과가 로드되지 않습니다. 이는 updateResults() 콜백이 모든 로딩 요청이 시작된 직후, allUsers 리스트에 데이터가 채워지기 전에 호출되기 때문입니다.
다음과 같이 수정하여 이를 해결하려고 시도할 수 있습니다:
val allUsers = mutableListOf<User>()
for ((index, repo) in repos.withIndex()) { // #1
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (index == repos.lastIndex) { // #2
updateResults(allUsers.aggregate())
}
}
}- 먼저 인덱스와 함께 저장소 리스트를 반복합니다(
#1). - 그런 다음 각 콜백에서 마지막 반복인지 확인합니다(
#2). - 마지막 반복인 경우 결과를 업데이트합니다.
하지만 이 코드 역시 목적을 달성하지 못합니다. 이유를 직접 찾아보거나 아래 솔루션을 확인하세요.
과제 3에 대한 두 번째 시도
로딩 요청이 동시에 시작되므로 마지막 요청의 결과가 마지막에 도착한다는 보장이 없습니다. 결과는 어떤 순서로든 올 수 있습니다.
따라서 현재 인덱스를 lastIndex와 비교하여 완료 조건으로 삼으면 일부 저장소의 결과를 잃어버릴 위험이 있습니다.
마지막 저장소를 처리하는 요청이 이전 요청들보다 빨리 반환되면(그럴 가능성이 큼), 더 오래 걸리는 요청들의 모든 결과가 유실될 것입니다.
이를 해결하는 한 가지 방법은 인덱스를 도입하고 모든 저장소가 처리되었는지 확인하는 것입니다:
val allUsers = Collections.synchronizedList(mutableListOf<User>())
val numberOfProcessed = AtomicInteger()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (numberOfProcessed.incrementAndGet() == repos.size) {
updateResults(allUsers.aggregate())
}
}
}이 코드는 동기화된 리스트 버전과 AtomicInteger()를 사용합니다. 왜냐하면 일반적으로 getRepoContributors() 요청을 처리하는 서로 다른 콜백들이 항상 동일한 스레드에서 호출된다는 보장이 없기 때문입니다.
과제 3에 대한 세 번째 시도
더 나은 방법은 CountDownLatch 클래스를 사용하는 것입니다. 이 클래스는 저장소의 수로 초기화된 카운터를 저장합니다. 각 저장소를 처리한 후 이 카운터를 감소시킵니다. 그런 다음 래치(latch)가 0이 될 때까지 기다렸다가 결과를 업데이트합니다:
val countDownLatch = CountDownLatch(repos.size)
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
// 저장소 처리
countDownLatch.countDown()
}
}
countDownLatch.await()
updateResults(allUsers.aggregate())결과는 메인 스레드에서 업데이트됩니다. 이는 로직을 자식 스레드에 위임하는 것보다 더 직접적입니다.
이 세 가지 시도를 검토해 본 결과, 콜백을 사용하여 올바른 코드를 작성하는 것은 결코 사소하지 않으며, 특히 여러 기본 스레드와 동기화가 발생하는 경우 에러가 발생하기 쉽다는 것을 알 수 있습니다.
추가 연습으로 RxJava 라이브러리를 사용한 반응형 접근 방식으로 동일한 로직을 구현해 볼 수 있습니다. RxJava 사용에 필요한 모든 의존성과 솔루션은 별도의
rx브랜치에서 찾을 수 있습니다. 적절한 비교를 위해 이 튜토리얼을 완료하고 제안된 Rx 버전을 구현하거나 확인해 볼 수도 있습니다.
일시 중단 함수 (Suspending functions)
일시 중단 함수를 사용하여 동일한 로직을 구현할 수 있습니다. Call<List<Repo>>를 반환하는 대신, 다음과 같이 API 호출을 일시 중단 함수로 정의합니다:
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): List<Repo>
}getOrgRepos()는suspend함수로 정의되었습니다. 일시 중단 함수를 사용하여 요청을 수행하면 기본 스레드가 차단되지 않습니다. 이것이 어떻게 작동하는지에 대한 자세한 내용은 다음 섹션에서 다룹니다.getOrgRepos()는Call을 반환하는 대신 결과를 직접 반환합니다. 결과가 실패하면 예외가 발생합니다.
또는 Retrofit을 사용하여 결과를 Response로 감싸서 반환할 수도 있습니다. 이 경우 결과 바디가 제공되며 수동으로 에러를 확인할 수 있습니다. 이 튜토리얼에서는 Response를 반환하는 버전을 사용합니다.
src/contributors/GitHubService.kt의 GitHubService 인터페이스에 다음 선언을 추가하세요:
interface GitHubService {
// getOrgReposCall 및 getRepoContributorsCall 선언
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): Response<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
suspend fun getRepoContributors(
@Path("owner") owner: String,
@Path("repo") repo: String
): Response<List<User>>
}과제 4
여러분의 과제는 기여자를 로드하는 함수의 코드를 변경하여 두 개의 새로운 일시 중단 함수인 getOrgRepos()와 getRepoContributors()를 사용하는 것입니다. 새로운 loadContributorsSuspend() 함수는 새 API를 사용하기 위해 suspend로 표시되어 있습니다.
일시 중단 함수는 아무 데서나 호출할 수 없습니다.
loadContributorsBlocking()에서 일시 중단 함수를 호출하면 "Suspend function 'getOrgRepos' should be called only from a coroutine or another suspend function"이라는 메시지와 함께 에러가 발생합니다.
src/tasks/Request1Blocking.kt에 정의된loadContributorsBlocking()의 구현 내용을src/tasks/Request4Suspend.kt에 정의된loadContributorsSuspend()로 복사합니다.Call을 반환하는 함수 대신 새로운 일시 중단 함수를 사용하도록 코드를 수정합니다.- SUSPEND 옵션을 선택하여 프로그램을 실행하고 GitHub 요청이 수행되는 동안 UI가 여전히 반응하는지 확인합니다.
과제 4 솔루션
.getOrgReposCall(req.org).execute()를 .getOrgRepos(req.org)로 바꾸고 두 번째 "contributors" 요청에 대해서도 동일한 교체를 반복합니다:
suspend fun loadContributorsSuspend(service: GitHubService, req: RequestData): List<User> {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
return repos.flatMap { repo ->
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}.aggregate()
}loadContributorsSuspend()는suspend함수로 정의되어야 합니다.- 이전에는
execute가Response를 반환했지만, 이제는 API 함수가Response를 직접 반환하므로 더 이상 호출할 필요가 없습니다. 이 세부 사항은 Retrofit 라이브러리에 국한된 것입니다. 다른 라이브러리에서는 API가 다르겠지만 개념은 동일합니다.
코루틴 (Coroutines)
일시 중단 함수를 사용한 코드는 "블로킹" 버전과 비슷해 보입니다. 블로킹 버전과의 큰 차이점은 스레드를 차단하는 대신 코루틴이 일시 중단된다는 것입니다:
block(차단) -> suspend(일시 중단)
thread(스레드) -> coroutine(코루틴)코루틴은 스레드에서 코드를 실행하는 방식과 유사하게 코루틴 상에서 코드를 실행할 수 있기 때문에 흔히 경량 스레드(lightweight threads)라고 불립니다. 이전에 차단되었던(그리고 피해야 했던) 작업들은 이제 대신 코루틴을 일시 중단시킬 수 있습니다.
새 코루틴 시작하기
src/contributors/Contributors.kt에서 loadContributorsSuspend()가 어떻게 사용되는지 보면 launch 내부에서 호출되는 것을 알 수 있습니다. launch는 람다를 인자로 받는 라이브러리 함수입니다:
launch {
val users = loadContributorsSuspend(req)
updateResults(users, startTime)
}여기서 launch는 데이터를 로드하고 결과를 표시하는 역할을 하는 새로운 계산(computation)을 시작합니다. 이 계산은 일시 중단 가능합니다. 네트워크 요청을 수행할 때 일시 중단되어 기본 스레드를 해제합니다. 네트워크 요청이 결과를 반환하면 계산이 재개됩니다.
이러한 일시 중단 가능한 계산을 _코루틴_이라고 합니다. 따라서 이 경우 launch는 데이터 로딩과 결과 표시를 담당하는 _새로운 코루틴을 시작_합니다.
코루틴은 스레드 위에서 실행되며 일시 중단될 수 있습니다. 코루틴이 일시 중단되면 해당 계산은 일시 정지되고 스레드에서 제거되어 메모리에 저장됩니다. 그동안 스레드는 다른 작업을 수행할 수 있도록 자유로워집니다:
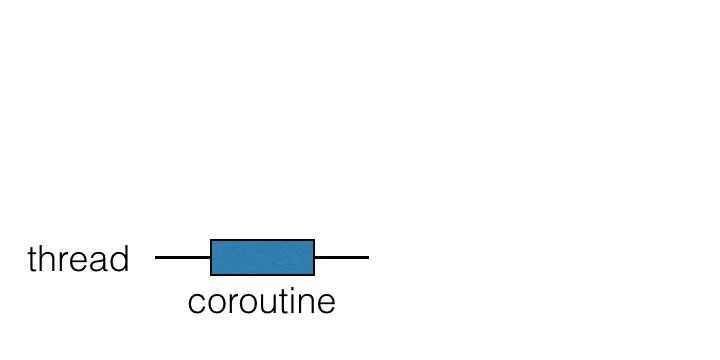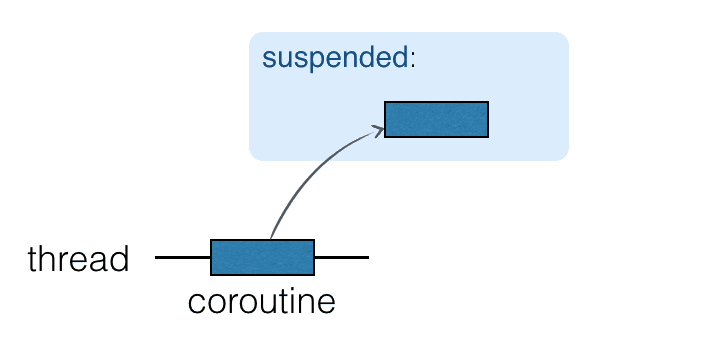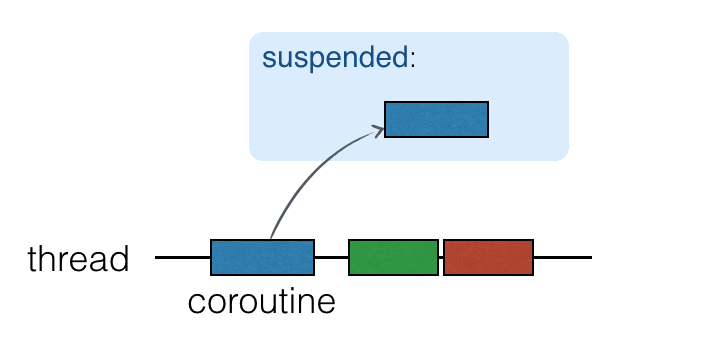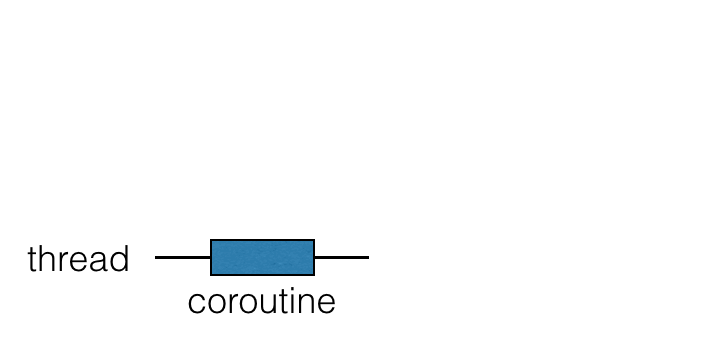
계산을 계속할 준비가 되면 스레드로 돌아옵니다 (반드시 동일한 스레드일 필요는 없습니다).
loadContributorsSuspend() 예제에서 각 "contributors" 요청은 이제 일시 중단 메커니즘을 사용하여 결과를 기다립니다. 먼저 새 요청이 전송됩니다. 그런 다음 응답을 기다리는 동안 launch 함수에 의해 시작된 전체 "load contributors" 코루틴이 일시 중단됩니다.
코루틴은 해당 응답을 받은 후에야 재개됩니다:
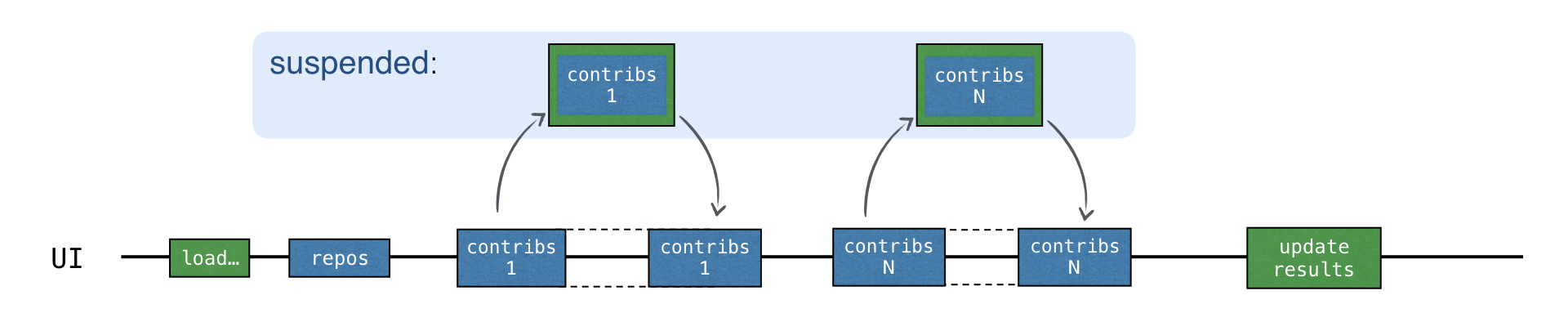
응답을 기다리는 동안 스레드는 자유롭게 다른 작업을 수행할 수 있습니다. 메인 UI 스레드에서 모든 요청이 발생함에도 불구하고 UI는 반응형을 유지합니다:
SUSPEND 옵션을 사용하여 프로그램을 실행합니다. 로그를 통해 모든 요청이 메인 UI 스레드에 전송되었음을 확인할 수 있습니다:
text2538 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos 2729 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - ts2kt: loaded 11 contributors 3029 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-koans: loaded 45 contributors ... 11252 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-coroutines-workshop: loaded 1 contributors로그에서 해당 코드가 어떤 코루틴에서 실행 중인지 확인할 수 있습니다. 이를 활성화하려면 Run | Edit configurations를 열고
-Dkotlinx.coroutines.debugVM 옵션을 추가하세요: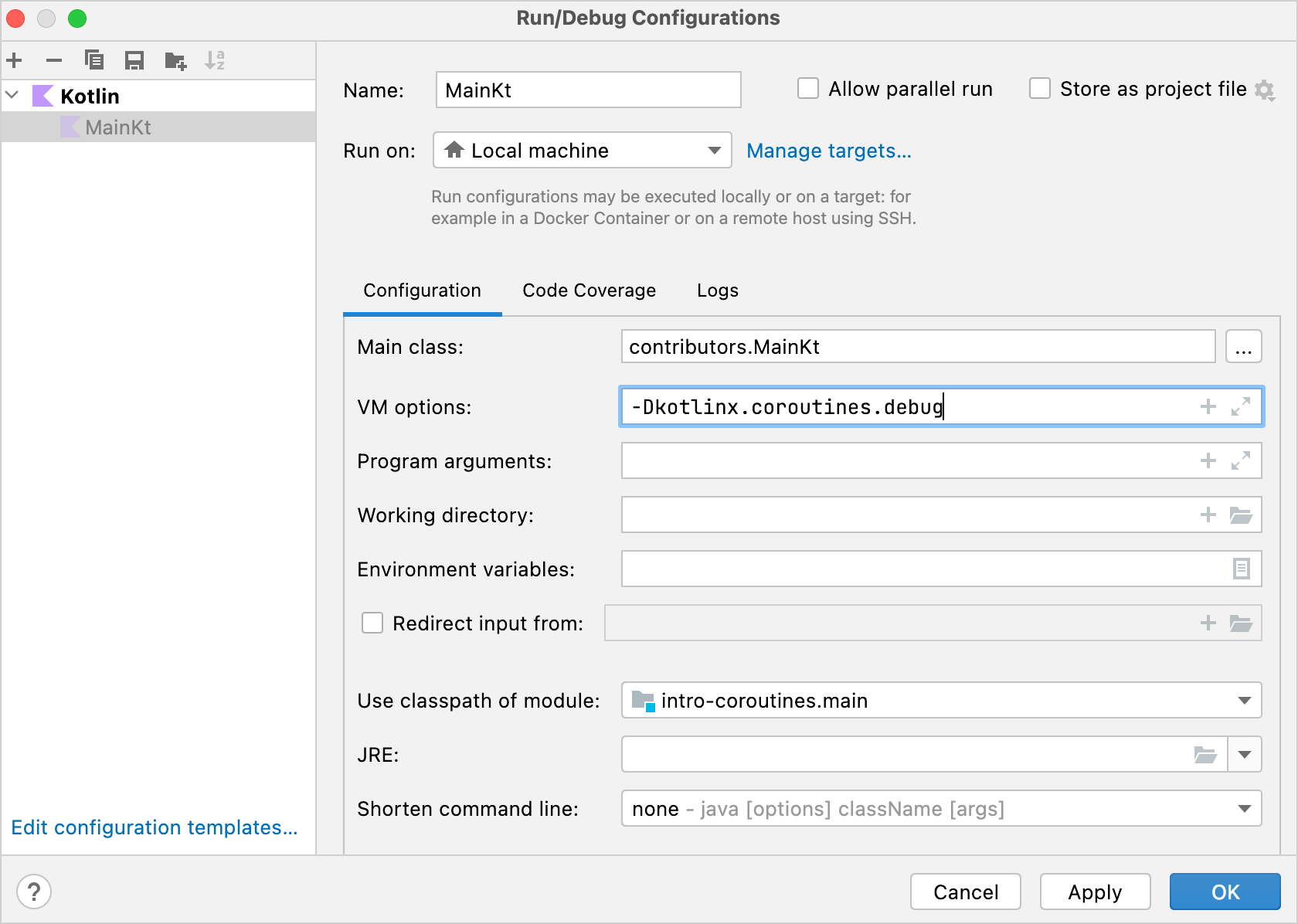
이 옵션으로
main()을 실행하면 스레드 이름에 코루틴 이름이 붙게 됩니다. 또한 모든 Kotlin 파일을 실행하기 위한 템플릿을 수정하여 이 옵션을 기본으로 활성화할 수도 있습니다.
이제 모든 코드는 위에서 언급한 @coroutine#1로 표시된 하나의 코루틴, 즉 "load contributors" 코루틴에서 실행됩니다. 결과를 기다리는 동안 코드가 순차적으로 작성되었기 때문에 다른 요청을 보내는 데 스레드를 재사용하지 않습니다. 이전 결과를 받은 후에야 새 요청이 전송됩니다.
일시 중단 함수는 스레드를 공정하게 다루며 "대기"를 위해 스레드를 차단하지 않습니다. 하지만 이것이 아직 동시성(concurrency)을 가져다주지는 않습니다.
동시성 (Concurrency)
Kotlin 코루틴은 스레드보다 훨씬 적은 리소스를 소모합니다. 새로운 계산을 비동기적으로 시작하고 싶을 때마다 스레드 대신 새로운 코루틴을 생성할 수 있습니다.
새 코루틴을 시작하려면 주요 코루틴 빌더 중 하나인 launch, async, 또는 runBlocking을 사용합니다. 라이브러리에 따라 추가적인 코루틴 빌더를 정의할 수도 있습니다.
async는 새 코루틴을 시작하고 Deferred 객체를 반환합니다. Deferred는 다른 언어에서 Future 또는 Promise와 같은 이름으로 알려진 개념을 나타냅니다. 이것은 계산 내용을 저장하지만, 최종 결과를 얻는 시점을 미룹니다(defer). 즉, 미래 어느 시점에 결과를 줄 것을 _약속(promise)_합니다.
async와 launch의 주요 차이점은 launch가 특정 결과를 반환할 것으로 기대되지 않는 계산을 시작하는 데 사용된다는 점입니다. launch는 코루틴을 나타내는 Job을 반환합니다. Job.join()을 호출하여 완료될 때까지 기다릴 수 있습니다.
Deferred는 Job을 확장하는 제네릭 타입입니다. async 호출은 람다가 무엇을 반환하느냐에 따라 Deferred<Int> 또는 Deferred<CustomType>을 반환할 수 있습니다 (람다 내부의 마지막 표현식이 결과가 됩니다).
코루틴의 결과를 얻으려면 Deferred 인스턴스에서 await()를 호출하면 됩니다. 결과를 기다리는 동안 await()가 호출된 코루틴은 일시 중단됩니다:
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferred: Deferred<Int> = async {
loadData()
}
println("waiting...")
println(deferred.await())
}
suspend fun loadData(): Int {
println("loading...")
delay(1000L)
println("loaded!")
return 42
}runBlocking은 일반 함수와 일시 중단 함수 사이, 또는 블로킹 세계와 논블로킹 세계 사이의 다리 역할을 합니다. 최상위 메인 코루틴을 시작하기 위한 어댑터로 작동합니다. 주로 main() 함수와 테스트에서 사용하도록 설계되었습니다.
코루틴을 더 잘 이해하려면 이 영상을 시청하세요.
지연된(deferred) 객체들의 리스트가 있는 경우, awaitAll()을 호출하여 모든 객체의 결과를 기다릴 수 있습니다:
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferreds: List<Deferred<Int>> = (1..3).map {
async {
delay(1000L * it)
println("Loading $it")
it
}
}
val sum = deferreds.awaitAll().sum()
println("$sum")
}각 "contributors" 요청이 새 코루틴에서 시작되면 모든 요청이 비동기적으로 시작됩니다. 이전 요청의 결과를 받기 전에 새 요청을 보낼 수 있습니다:
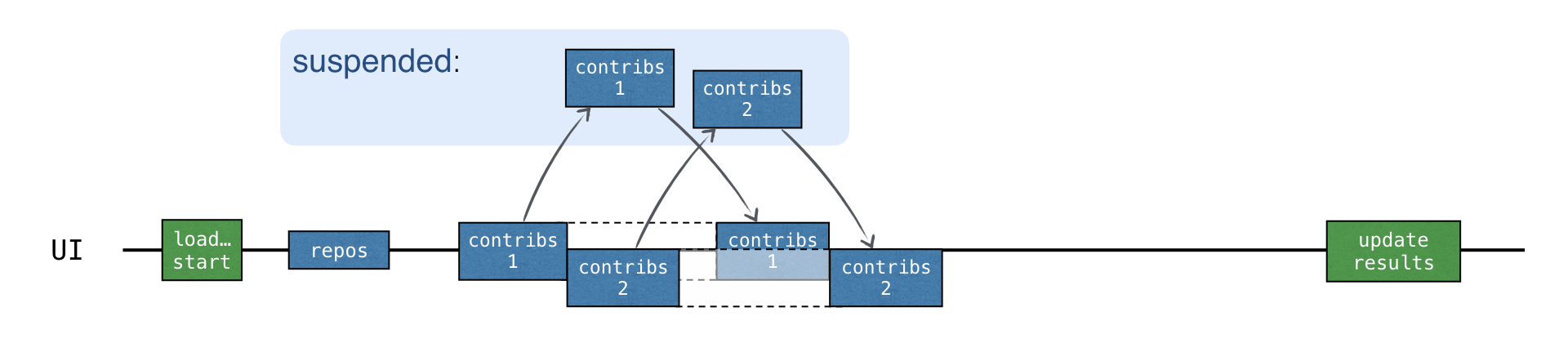
전체 로딩 시간은 CALLBACKS 버전과 거의 동일하지만 콜백이 필요하지 않습니다. 더욱이 async는 코드에서 어느 부분이 동시에 실행되는지 명시적으로 강조해 줍니다.
과제 5
Request5Concurrent.kt 파일에서 이전의 loadContributorsSuspend() 함수를 사용하여 loadContributorsConcurrent() 함수를 구현하세요.
과제 5를 위한 팁
새 코루틴은 코루틴 스코프 내에서만 시작할 수 있습니다. loadContributorsSuspend()의 내용을 coroutineScope 호출 내부로 복사하여 그 안에서 async 함수를 호출할 수 있도록 하세요:
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
// ...
}다음 스키마를 기반으로 해결책을 작성하세요:
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
// 각 저장소에 대한 기여자 로드
}
}
deferreds.awaitAll() // List<List<User>>과제 5 솔루션
각 "contributors" 요청을 async로 감싸 저장소 수만큼 코루틴을 생성합니다. async는 Deferred<List<User>>를 반환합니다. 코루틴을 생성하는 것은 리소스를 많이 소모하지 않으므로 필요한 만큼 생성해도 문제가 되지 않습니다.
이제
map결과가 리스트의 리스트가 아닌Deferred객체의 리스트이므로 더 이상flatMap을 사용할 수 없습니다.awaitAll()은List<List<User>>를 반환하므로 결과를 얻으려면flatten().aggregate()를 호출하세요:kotlinsuspend fun loadContributorsConcurrent( service: GitHubService, req: RequestData ): List<User> = coroutineScope { val repos = service .getOrgRepos(req.org) .also { logRepos(req, it) } .bodyList() val deferreds: List<Deferred<List<User>>> = repos.map { repo -> async { service.getRepoContributors(req.org, repo.name) .also { logUsers(repo, it) } .bodyList() } } deferreds.awaitAll().flatten().aggregate() }코드를 실행하고 로그를 확인합니다. 멀티스레딩이 아직 적용되지 않았기 때문에 모든 코루틴이 여전히 메인 UI 스레드에서 실행되지만, 코루틴을 동시에 실행하는 이점을 이미 확인할 수 있습니다.
이 코드를 공용 스레드 풀의 서로 다른 스레드에서 "contributors" 코루틴이 실행되도록 변경하려면
async함수의 컨텍스트 인자로Dispatchers.Default를 지정하세요:kotlinasync(Dispatchers.Default) { }CoroutineDispatcher는 해당 코루틴이 어느 스레드 또는 스레드들에서 실행되어야 하는지 결정합니다. 인자로 지정하지 않으면async는 외부 스코프의 디스패처를 사용합니다.Dispatchers.Default는 JVM의 공유 스레드 풀을 나타냅니다. 이 풀은 병렬 실행을 위한 수단을 제공합니다. 사용 가능한 CPU 코어 수만큼의 스레드로 구성되지만, 코어가 하나뿐이더라도 최소 두 개의 스레드를 가집니다.
loadContributorsConcurrent()함수의 코드를 수정하여 공용 스레드 풀의 서로 다른 스레드에서 새 코루틴을 시작하도록 하세요. 또한 요청을 보내기 전에 추가 로깅을 추가하세요:kotlinasync(Dispatchers.Default) { log("starting loading for ${repo.name}") service.getRepoContributors(req.org, repo.name) .also { logUsers(repo, it) } .bodyList() }프로그램을 다시 한 번 실행합니다. 로그에서 각 코루틴이 스레드 풀의 한 스레드에서 시작되고 다른 스레드에서 재개될 수 있음을 확인할 수 있습니다:
text1946 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans 1946 [DefaultDispatcher-worker-3 @coroutine#5] INFO Contributors - starting loading for dokka 1946 [DefaultDispatcher-worker-1 @coroutine#3] INFO Contributors - starting loading for ts2kt ... 2178 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors 2569 [DefaultDispatcher-worker-1 @coroutine#5] INFO Contributors - dokka: loaded 36 contributors 2821 [DefaultDispatcher-worker-2 @coroutine#3] INFO Contributors - ts2kt: loaded 11 contributors예를 들어, 이 로그 발췌문에서
coroutine#4는worker-2스레드에서 시작되어worker-1스레드에서 계속되었습니다.
src/contributors/Contributors.kt에서 CONCURRENT 옵션의 구현을 확인하세요:
메인 UI 스레드에서만 코루틴을 실행하려면
Dispatchers.Main을 인자로 지정하세요:kotlinlaunch(Dispatchers.Main) { updateResults() }- 메인 스레드에서 새 코루틴을 시작할 때 메인 스레드가 바쁘면 코루틴은 일시 중단되고 이 스레드에서 실행되도록 스케줄링됩니다. 코루틴은 스레드가 자유로워질 때만 재개됩니다.
- 각 엔드포인트에서 디스패처를 명시적으로 지정하기보다는 외부 스코프의 디스패처를 사용하는 것이 좋은 관행으로 간주됩니다.
Dispatchers.Default를 인자로 전달하지 않고loadContributorsConcurrent()를 정의하면Default디스패처, 메인 UI 스레드 또는 커스텀 디스패처 등 어떤 컨텍스트에서도 이 함수를 호출할 수 있습니다. - 나중에 보겠지만 테스트에서
loadContributorsConcurrent()를 호출할 때TestDispatcher컨텍스트에서 호출할 수 있어 테스트가 단순해집니다. 이를 통해 해결책이 훨씬 유연해집니다.
호출자 측에서 디스패처를 지정하려면
loadContributorsConcurrent가 상속된 컨텍스트에서 코루틴을 시작하게 두면서 프로젝트에 다음 변경 사항을 적용하세요:kotlinlaunch(Dispatchers.Default) { val users = loadContributorsConcurrent(service, req) withContext(Dispatchers.Main) { updateResults(users, startTime) } }updateResults()는 메인 UI 스레드에서 호출되어야 하므로Dispatchers.Main컨텍스트로 호출합니다.withContext()는 지정된 코루틴 컨텍스트로 주어진 코드를 호출하고, 완료될 때까지 일시 중단된 후 결과를 반환합니다. 이를 표현하는 대안적이지만 더 장황한 방법은 새 코루틴을 시작하고 완료될 때까지 명시적으로 기다리는(일시 중단하여) 것입니다:launch(context) { ... }.join().
코드를 실행하고 코루틴이 스레드 풀의 스레드에서 실행되는지 확인합니다.
구조화된 동시성 (Structured concurrency)
- _코루틴 스코프(coroutine scope)_는 서로 다른 코루틴 간의 구조와 부모-자식 관계를 담당합니다. 새로운 코루틴은 일반적으로 스코프 내부에서 시작되어야 합니다.
- _코루틴 컨텍스트(coroutine context)_는 코루틴 커스텀 이름이나 코루틴이 스케줄링되어야 하는 스레드를 지정하는 디스패처와 같이 주어진 코루틴을 실행하는 데 사용되는 추가적인 기술 정보를 저장합니다.
launch, async, 또는 runBlocking을 사용하여 새 코루틴을 시작할 때, 이들은 자동으로 해당 스코프를 생성합니다. 이 모든 함수는 수신 객체가 있는 람다를 인자로 받으며, CoroutineScope가 암시적 수신 객체 타입입니다:
launch { /* this: CoroutineScope */ }- 새로운 코루틴은 스코프 내에서만 시작할 수 있습니다.
launch와async는CoroutineScope의 확장 함수로 선언되어 있으므로 호출할 때 항상 암시적 또는 명시적 수신 객체가 전달되어야 합니다.runBlocking은 최상위 함수로 정의되어 있기 때문에 여기서 시작된 코루틴이 유일한 예외입니다. 하지만 현재 스레드를 차단하기 때문에 주로main()함수와 테스트에서 브리지 함수로 사용되도록 의도되었습니다.
runBlocking, launch, 또는 async 내부의 새 코루틴은 스코프 내에서 자동으로 시작됩니다:
import kotlinx.coroutines.*
fun main() = runBlocking { /* this: CoroutineScope */
launch { /* ... */ }
// 다음과 같음:
this.launch { /* ... */ }
}runBlocking 내부에서 launch를 호출하면 CoroutineScope 타입의 암시적 수신 객체에 대한 확장 함수로 호출됩니다. 또는 명시적으로 this.launch라고 쓸 수도 있습니다.
중첩된 코루틴(이 예제에서는 launch로 시작된 것)은 외부 코루틴(runBlocking으로 시작된 것)의 자식으로 간주될 수 있습니다. 이 "부모-자식" 관계는 스코프를 통해 작동합니다. 자식 코루틴은 부모 코루틴에 해당하는 스코프에서 시작됩니다.
coroutineScope 함수를 사용하면 새 코루틴을 시작하지 않고도 새 스코프를 만들 수 있습니다. 외부 스코프에 접근할 수 없는 suspend 함수 내부에서 구조화된 방식으로 새 코루틴을 시작하려면, 이 suspend 함수가 호출된 외부 스코프의 자식이 자동으로 되는 새 코루틴 스코프를 만들 수 있습니다. loadContributorsConcurrent()가 좋은 예입니다.
GlobalScope.async 또는 GlobalScope.launch를 사용하여 글로벌 스코프에서 새 코루틴을 시작할 수도 있습니다. 이렇게 하면 최상위 수준의 "독립적인" 코루틴이 생성됩니다.
코루틴 구조의 이면에 있는 메커니즘을 _구조화된 동시성(structured concurrency)_이라고 합니다. 이는 글로벌 스코프에 비해 다음과 같은 이점을 제공합니다:
- 스코프는 일반적으로 자식 코루틴들을 책임지며, 자식 코루틴들의 수명은 스코프의 수명과 연결됩니다.
- 문제가 발생하거나 사용자가 마음을 바꿔 작업을 취소하기로 결정한 경우 스코프가 자동으로 자식 코루틴들을 취소할 수 있습니다.
- 스코프는 모든 자식 코루틴이 완료될 때까지 자동으로 기다립니다. 따라서 스코프가 코루틴에 해당하는 경우, 부모 코루틴은 스코프 내에서 실행된 모든 코루틴이 완료될 때까지 완료되지 않습니다.
GlobalScope.async를 사용하면 여러 코루틴을 더 작은 스코프로 묶는 구조가 없습니다. 글로벌 스코프에서 시작된 코루틴은 모두 독립적이며, 수명은 전체 애플리케이션의 수명에 의해서만 제한됩니다. 글로벌 스코프에서 시작된 코루틴에 대한 참조를 저장하고 완료를 기다리거나 명시적으로 취소하는 것이 가능하지만, 구조화된 동시성에서처럼 자동으로 일어나지는 않습니다.
기여자 로딩 취소하기
기여자 목록을 로드하는 함수를 두 가지 버전으로 만드세요. 부모 코루틴을 취소하려고 할 때 두 버전이 어떻게 작동하는지 비교해 보세요. 첫 번째 버전은 coroutineScope를 사용하여 모든 자식 코루틴을 시작하고, 두 번째 버전은 GlobalScope를 사용합니다.
Request5Concurrent.kt에서loadContributorsConcurrent()함수에 3초의 지연(delay)을 추가합니다:kotlinsuspend fun loadContributorsConcurrent( service: GitHubService, req: RequestData ): List<User> = coroutineScope { // ... async { log("starting loading for ${repo.name}") delay(3000) // 저장소 기여자 로드 } // ... }이 지연은 요청을 보내는 모든 코루틴에 영향을 미치므로 코루틴이 시작된 후 요청이 전송되기 전에 로딩을 취소할 충분한 시간을 제공합니다.
두 번째 로딩 함수 버전을 만듭니다.
loadContributorsConcurrent()의 구현을Request5NotCancellable.kt의loadContributorsNotCancellable()로 복사한 다음 새coroutineScope생성을 제거합니다.이제
async호출이 해결되지 않으므로GlobalScope.async를 사용하여 시작합니다:kotlinsuspend fun loadContributorsNotCancellable( service: GitHubService, req: RequestData ): List<User> { // #1 // ... GlobalScope.async { // #2 log("starting loading for ${repo.name}") // 저장소 기여자 로드 } // ... return deferreds.awaitAll().flatten().aggregate() // #3 }- 함수는 이제 람다 내부의 마지막 표현식이 아니라 결과를 직접 반환합니다(라인
#1및#3). - 모든 "contributors" 코루틴은 코루틴 스코프의 자식이 아니라
GlobalScope내부에서 시작됩니다(라인#2).
- 함수는 이제 람다 내부의 마지막 표현식이 아니라 결과를 직접 반환합니다(라인
프로그램을 실행하고 기여자를 로드하기 위해 CONCURRENT 옵션을 선택합니다.
모든 "contributors" 코루틴이 시작될 때까지 기다린 다음 _Cancel_을 클릭합니다. 로그에 새로운 결과가 표시되지 않는 것으로 보아 모든 요청이 실제로 취소되었음을 알 수 있습니다:
text2896 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 40 repos 2901 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans ... 2909 [DefaultDispatcher-worker-5 @coroutine#36] INFO Contributors - starting loading for mpp-example /* 'cancel' 클릭 */ /* 더 이상 요청이 전송되지 않음 */5단계를 반복하되 이번에는
NOT_CANCELLABLE옵션을 선택합니다:text2570 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos 2579 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - starting loading for kotlin-koans ... 2586 [DefaultDispatcher-worker-6 @coroutine#36] INFO Contributors - starting loading for mpp-example /* 'cancel' 클릭 */ /* 하지만 모든 요청이 여전히 전송됨: */ 6402 [DefaultDispatcher-worker-5 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors ... 9555 [DefaultDispatcher-worker-8 @coroutine#36] INFO Contributors - mpp-example: loaded 8 contributors이 경우 어떤 코루틴도 취소되지 않으며 모든 요청이 여전히 전송됩니다.
"contributors" 프로그램에서 취소가 어떻게 트리거되는지 확인하세요. Cancel 버튼을 클릭하면 메인 "loading" 코루틴이 명시적으로 취소되고 자식 코루틴들이 자동으로 취소됩니다:
kotlininterface Contributors { fun loadContributors() { // ... when (getSelectedVariant()) { CONCURRENT -> { launch { val users = loadContributorsConcurrent(service, req) updateResults(users, startTime) }.setUpCancellation() // #1 } } } private fun Job.setUpCancellation() { val loadingJob = this // #2 // 'cancel' 버튼이 클릭되면 로딩 잡(job)을 취소함: val listener = ActionListener { loadingJob.cancel() // #3 updateLoadingStatus(CANCELED) } // 'cancel' 버튼에 리스너 추가: addCancelListener(listener) // 로딩 잡이 완료된 후 // 상태를 업데이트하고 리스너를 제거함 } }
launch 함수는 Job 인스턴스를 반환합니다. Job은 모든 데이터를 로드하고 결과를 업데이트하는 "loading coroutine"에 대한 참조를 저장합니다. 여기에 Job 인스턴스를 수신 객체로 전달하여 setUpCancellation() 확장 함수를 호출할 수 있습니다(#1 라인).
이를 표현하는 또 다른 방법은 다음과 같이 명시적으로 쓰는 것입니다:
val job = launch { }
job.setUpCancellation()- 가독성을 위해
setUpCancellation()함수 내부에서 수신 객체를 새로운loadingJob변수로 참조할 수 있습니다(#2라인). - 그런 다음 Cancel 버튼에 리스너를 추가하여 클릭 시
loadingJob이 취소되도록 할 수 있습니다(#3라인).
구조화된 동시성을 사용하면 부모 코루틴만 취소하면 되며, 이는 자동으로 모든 자식 코루틴에 취소를 전파합니다.
외부 스코프의 컨텍스트 사용하기
주어진 스코프 내부에서 새 코루틴을 시작하면 모든 코루틴이 동일한 컨텍스트로 실행되도록 보장하기가 훨씬 쉽습니다. 또한 필요한 경우 컨텍스트를 교체하는 것도 훨씬 쉽습니다.
이제 외부 스코프의 디스패처를 사용하는 방법을 알아볼 차례입니다. coroutineScope나 코루틴 빌더에 의해 생성된 새 스코프는 항상 외부 스코프에서 컨텍스트를 상속합니다. 이 경우 외부 스코프는 suspend loadContributorsConcurrent() 함수가 호출된 스코프입니다:
launch(Dispatchers.Default) { // 외부 스코프
val users = loadContributorsConcurrent(service, req)
// ...
}모든 중첩된 코루틴은 상속된 컨텍스트로 자동으로 시작됩니다. 디스패처는 이 컨텍스트의 일부입니다. 그렇기 때문에 async로 시작된 모든 코루틴은 디폴트(default) 디스패처 컨텍스트로 시작됩니다:
suspend fun loadContributorsConcurrent(
service: GitHubService, req: RequestData
): List<User> = coroutineScope {
// 이 스코프는 외부 스코프로부터 컨텍스트를 상속함
// ...
async { // 상속된 컨텍스트로 시작된 중첩된 코루틴
// ...
}
// ...
}구조화된 동시성을 사용하면 최상위 코루틴을 생성할 때 주요 컨텍스트 요소(예: 디스패처)를 한 번만 지정할 수 있습니다. 그러면 모든 중첩된 코루틴이 컨텍스트를 상속하고 필요한 경우에만 수정합니다.
안드로이드 앱과 같은 UI 애플리케이션용 코루틴 코드를 작성할 때, 최상위 코루틴에 기본적으로
CoroutineDispatchers.Main을 사용하고 다른 스레드에서 코드를 실행해야 할 때만 명시적으로 다른 디스패처를 지정하는 것이 일반적인 관행입니다.
진행 상황 표시하기 (Showing progress)
일부 저장소에 대한 정보가 꽤 빨리 로드됨에도 불구하고, 사용자는 모든 데이터가 로드된 후에야 결과 리스트를 보게 됩니다. 그때까지는 진행 상황을 나타내는 로더 아이콘만 돌아가고, 현재 상태나 어떤 기여자가 이미 로드되었는지에 대한 정보는 없습니다.
중간 결과를 더 일찍 보여주고 각 저장소에 대한 데이터를 로드한 후 모든 기여자를 표시할 수 있습니다:
이 기능을 구현하려면 src/tasks/Request6Progress.kt에서 UI를 업데이트하는 로직을 콜백으로 전달하여 각 중간 상태에서 호출되도록 해야 합니다:
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
// 데이터 로딩
// 중간 상태에서 `updateResults()` 호출
}호출 지점인 Contributors.kt에서 PROGRESS 옵션의 경우 Main 스레드에서 결과를 업데이트하도록 콜백이 전달됩니다:
launch(Dispatchers.Default) {
loadContributorsProgress(service, req) { users, completed ->
withContext(Dispatchers.Main) {
updateResults(users, startTime, completed)
}
}
}loadContributorsProgress()에서updateResults()파라미터는suspend로 선언됩니다. 해당 람다 인자 내부에서suspend함수인withContext를 호출해야 하기 때문입니다.updateResults()콜백은 로딩이 완료되었고 결과가 최종적인지 여부를 지정하는 추가적인 Boolean 파라미터를 인자로 받습니다.
과제 6
Request6Progress.kt 파일에서 중간 진행 상황을 보여주는 loadContributorsProgress() 함수를 구현하세요. Request4Suspend.kt의 loadContributorsSuspend() 함수를 기반으로 작성하세요.
- 동시성을 사용하지 않는 단순한 버전을 사용하세요. 동시성은 다음 섹션에서 추가할 것입니다.
- 중간 기여자 리스트는 단순히 각 저장소에 대해 로드된 사용자 리스트가 아니라 "집계된(aggregated)" 상태로 표시되어야 합니다.
- 각 사용자의 총 기여 횟수는 새로운 저장소의 데이터가 로드될 때마다 증가해야 합니다.
과제 6 솔루션
집계된 상태의 중간 로드 기여자 리스트를 저장하기 위해 사용자 리스트를 저장하는 allUsers 변수를 정의한 다음, 각 새로운 저장소의 기여자가 로드된 후에 업데이트합니다:
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
var allUsers = emptyList<User>()
for ((index, repo) in repos.withIndex()) {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, index == repos.lastIndex)
}
}순차 vs 동시 (Consecutive vs concurrent)
updateResults() 콜백은 각 요청이 완료된 후에 호출됩니다:
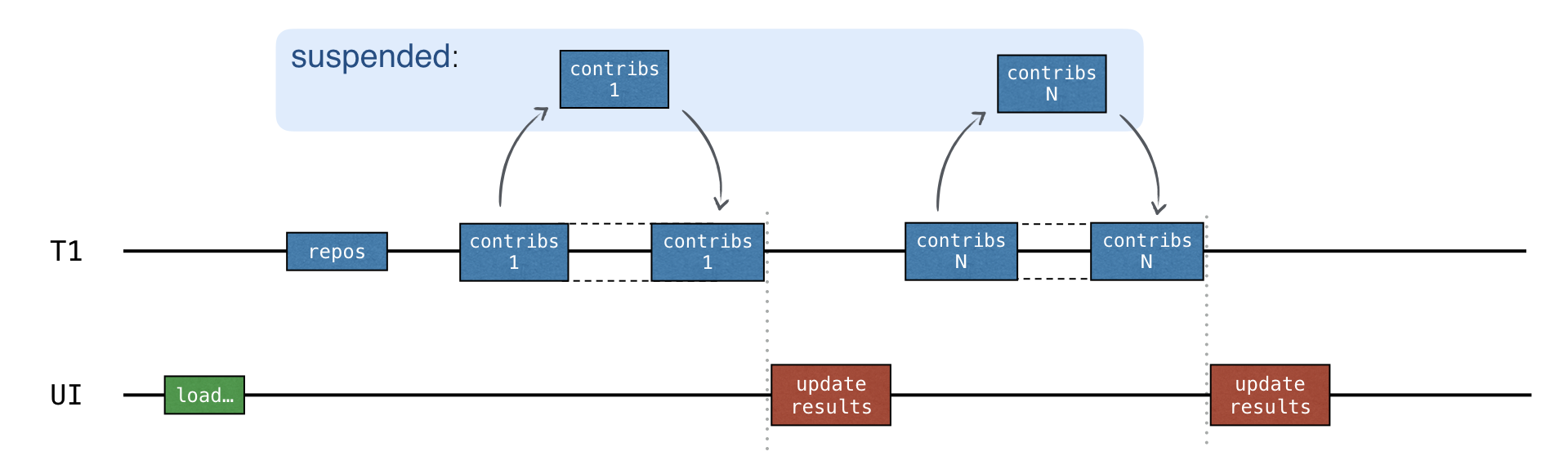
이 코드는 동시성을 포함하지 않습니다. 순차적이므로 동기화가 필요하지 않습니다.
가장 좋은 옵션은 요청을 동시에 보내고 각 저장소에 대한 응답을 받은 후 중간 결과를 업데이트하는 것입니다:
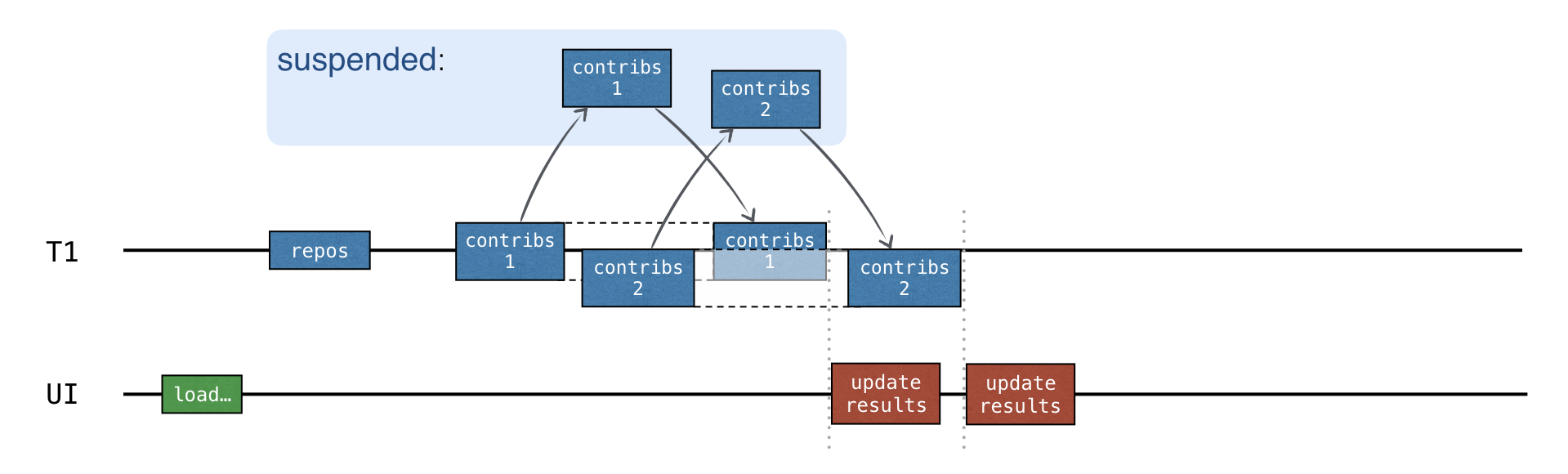
동시성을 추가하려면 _채널(channels)_을 사용하세요.
채널 (Channels)
공유된 가변 상태(shared mutable state)를 사용하여 코드를 작성하는 것은 꽤 어렵고 에러가 발생하기 쉽습니다(콜백을 사용한 해결책처럼). 더 간단한 방법은 공통된 가변 상태를 사용하는 대신 통신을 통해 정보를 공유하는 것입니다. 코루틴은 _채널_을 통해 서로 통신할 수 있습니다.
채널은 코루틴 간에 데이터를 전달할 수 있게 해주는 통신 프리미티브(primitives)입니다. 한 코루틴은 채널로 정보를 보낼(send) 수 있고, 다른 코루틴은 그 채널로부터 정보를 받을(receive) 수 있습니다:

정보를 보내는(생성하는) 코루틴은 흔히 프로듀서(producer, 생산자)라고 불리고, 정보를 받는(소비하는) 코루틴은 컨슈머(consumer, 소비자)라고 불립니다. 하나 또는 여러 개의 코루틴이 동일한 채널로 정보를 보낼 수 있고, 하나 또는 여러 개의 코루틴이 동일한 채널로부터 데이터를 받을 수 있습니다:
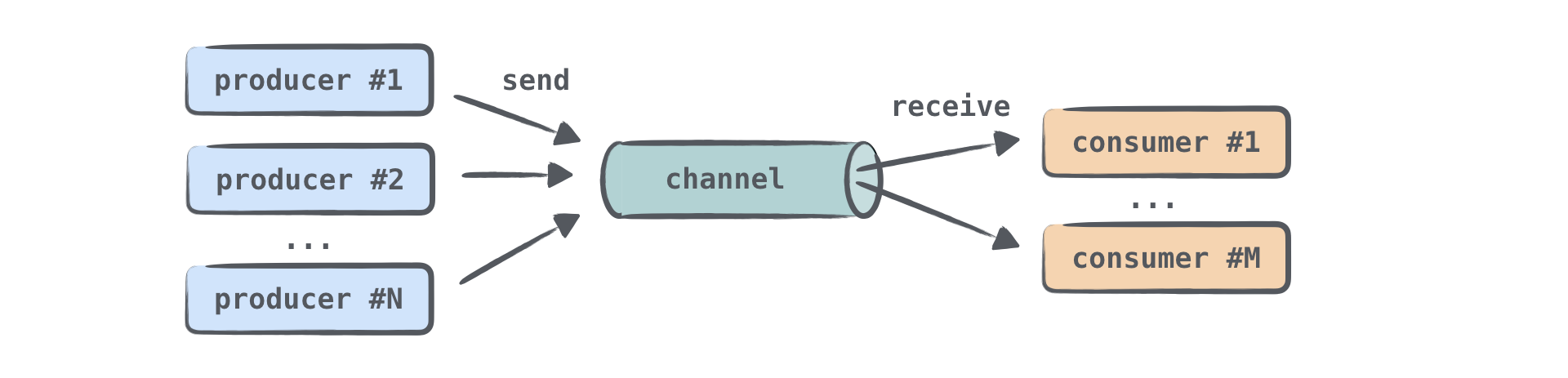
여러 코루틴이 동일한 채널로부터 정보를 받을 때, 각 요소는 소비자 중 하나에 의해 단 한 번만 처리됩니다. 요소가 처리되면 즉시 채널에서 제거됩니다.
채널을 요소들의 컬렉션, 더 정확하게는 한쪽 끝에서 요소가 추가되고 다른 쪽 끝에서 받는 큐(queue)와 비슷하다고 생각할 수 있습니다. 하지만 중요한 차이점이 있습니다. 동기화된 버전의 컬렉션과 달리, 채널은 send()와 receive() 작업을 _일시 중단_할 수 있습니다. 이는 채널이 비어 있거나 가득 찼을 때 발생합니다. 채널 크기에 상한선이 있는 경우 채널이 가득 찰 수 있습니다.
Channel은 세 개의 서로 다른 인터페이스로 표현됩니다: SendChannel, ReceiveChannel, 그리고 앞의 두 인터페이스를 확장하는 Channel입니다. 보통 채널을 생성한 뒤 프로듀서에게는 SendChannel 인스턴스로 제공하여 정보를 보낼 수만 있게 합니다. 컨슈머에게는 ReceiveChannel 인스턴스로 제공하여 받을 수만 있게 합니다. send와 receive 메서드 모두 suspend로 선언되어 있습니다:
interface SendChannel<in E> {
suspend fun send(element: E)
fun close(): Boolean
}
interface ReceiveChannel<out E> {
suspend fun receive(): E
}
interface Channel<E> : SendChannel<E>, ReceiveChannel<E>프로듀서는 더 이상 요소가 오지 않음을 나타내기 위해 채널을 닫을 수 있습니다.
라이브러리에는 여러 유형의 채널이 정의되어 있습니다. 이들은 내부에 몇 개의 요소를 저장할 수 있는지, 그리고 send() 호출이 일시 중단될 수 있는지 여부가 다릅니다. 모든 채널 유형에 대해 receive() 호출은 유사하게 작동합니다. 채널이 비어 있지 않으면 요소를 받고, 그렇지 않으면 일시 중단됩니다.
무제한 채널 (Unlimited channel)
무제한 채널은 큐와 가장 유사합니다. 프로듀서는 이 채널에 요소를 보낼 수 있으며 채널은 무한히 계속 커질 것입니다. send() 호출은 결코 일시 중단되지 않습니다. 프로그램 메모리가 부족해지면 OutOfMemoryException이 발생합니다. 무제한 채널과 큐의 차이점은 소비자가 비어 있는 채널에서 받으려고 할 때 새로운 요소가 보내질 때까지 일시 중단된다는 점입니다.

버퍼 채널 (Buffered channel)
버퍼 채널의 크기는 지정된 숫자로 제한됩니다. 프로듀서는 크기 제한에 도달할 때까지 이 채널에 요소를 보낼 수 있습니다. 모든 요소는 내부에 저장됩니다. 채널이 가득 차면 다음 send 호출은 여유 공간이 생길 때까지 일시 중단됩니다.

랑데뷰 채널 (Rendezvous channel)
"랑데뷰(Rendezvous)" 채널은 버퍼가 없는 채널로, 크기가 0인 버퍼 채널과 같습니다. 두 함수(send() 또는 receive()) 중 하나는 항상 다른 함수가 호출될 때까지 일시 중단됩니다.
send() 함수가 호출되었는데 요소를 처리할 준비가 된 일시 중단된 receive() 호출이 없다면 send()는 일시 중단됩니다. 마찬가지로 receive() 함수가 호출되었는데 채널이 비어 있거나 요소를 보낼 준비가 된 일시 중단된 send() 호출이 없다면 receive() 호출은 일시 중단됩니다.
"랑데뷰"라는 이름("정해진 시간과 장소에서의 만남")은 send()와 receive()가 "제시간에 만나야" 한다는 사실을 의미합니다.

콘플레이티드 채널 (Conflated channel)
콘플레이티드(Conflated, 결합된) 채널에 전송된 새 요소는 이전에 전송된 요소를 덮어쓰므로 수신자는 항상 최신 요소만 받게 됩니다. send() 호출은 절대 일시 중단되지 않습니다.

채널을 생성할 때 유형이나 버퍼 크기를 지정하세요 (버퍼 채널이 필요한 경우):
val rendezvousChannel = Channel<String>()
val bufferedChannel = Channel<String>(10)
val conflatedChannel = Channel<String>(CONFLATED)
val unlimitedChannel = Channel<String>(UNLIMITED)기본적으로는 "랑데뷰" 채널이 생성됩니다.
다음 과제에서는 "랑데뷰" 채널, 두 개의 프로듀서 코루틴, 하나의 컨슈머 코루틴을 생성할 것입니다:
import kotlinx.coroutines.channels.Channel
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
val channel = Channel<String>()
launch {
channel.send("A1")
channel.send("A2")
log("A done")
}
launch {
channel.send("B1")
log("B done")
}
launch {
repeat(3) {
val x = channel.receive()
log(x)
}
}
}
fun log(message: Any?) {
println("[${Thread.currentThread().name}] $message")
}채널을 더 잘 이해하려면 이 영상을 시청하세요.
과제 7
src/tasks/Request7Channels.kt에서 모든 GitHub 기여자를 동시에 요청하는 동시에 중간 진행 상황을 보여주는 loadContributorsChannels() 함수를 구현하세요.
이전 함수들인 Request5Concurrent.kt의 loadContributorsConcurrent()와 Request6Progress.kt의 loadContributorsProgress()를 사용하세요.
과제 7을 위한 팁
여러 저장소에 대한 기여자 리스트를 동시에 받는 서로 다른 코루틴들은 받은 모든 결과를 동일한 채널로 보낼 수 있습니다:
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = TODO()
// ...
channel.send(users)
}
}그런 다음 이 채널의 요소들을 하나씩 받아 처리할 수 있습니다:
repeat(repos.size) {
val users = channel.receive()
// ...
}receive() 호출이 순차적이므로 추가적인 동기화는 필요하지 않습니다.
과제 7 솔루션
loadContributorsProgress() 함수와 마찬가지로, "모든 기여자" 리스트의 중간 상태를 저장할 allUsers 변수를 생성할 수 있습니다. 채널로부터 받은 각 새로운 리스트는 전체 사용자 리스트에 추가됩니다. 결과를 집계하고 updateResults 콜백을 사용하여 상태를 업데이트합니다:
suspend fun loadContributorsChannels(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
channel.send(users)
}
}
var allUsers = emptyList<User>()
repeat(repos.size) {
val users = channel.receive()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, it == repos.lastIndex)
}
}- 서로 다른 저장소에 대한 결과는 준비되는 대로 채널에 추가됩니다. 처음에는 모든 요청이 전송되고 데이터가 수신되지 않은 상태이므로
receive()호출이 일시 중단됩니다. 이 경우 전체 "load contributors" 코루틴이 일시 중단됩니다. - 그런 다음 사용자 리스트가 채널로 전송되면 "load contributors" 코루틴이 재개되고,
receive()호출이 이 리스트를 반환하며 결과가 즉시 업데이트됩니다.
이제 프로그램을 실행하고 CHANNELS 옵션을 선택하여 기여자를 로드하고 결과를 확인할 수 있습니다.
코루틴이나 채널이 동시성에서 오는 복잡성을 완전히 제거해 주지는 않지만, 무슨 일이 일어나고 있는지 이해해야 할 때 삶을 더 편하게 만들어 줍니다.
코루틴 테스트하기
이제 동시 코루틴 해결책이 suspend 함수 해결책보다 빠른지, 그리고 채널 해결책이 단순 "progress" 해결책보다 빠른지 모든 해결책을 테스트해 봅시다.
다음 과제에서는 해결책들의 총 실행 시간을 비교할 것입니다. GitHub 서비스를 모의(mock)하고 이 서비스가 지정된 타임아웃 후에 결과를 반환하도록 만들 것입니다:
repos request - 1000ms 지연 내에 응답 반환
repo-1 - 1000ms 지연
repo-2 - 1200ms 지연
repo-3 - 800ms 지연suspend 함수를 사용한 순차적 해결책은 약 4000ms(4000 = 1000 + (1000 + 1200 + 800))가 걸려야 합니다. 동시 해결책은 약 2200ms(2200 = 1000 + max(1000, 1200, 800))가 걸려야 합니다.
진행 상황을 보여주는 해결책의 경우 타임스탬프와 함께 중간 결과도 확인할 수 있습니다.
해당 테스트 데이터는 test/contributors/testData.kt에 정의되어 있으며, Request4SuspendKtTest, Request7ChannelsKtTest 등의 파일에는 모의 서비스 호출을 사용하는 직접적인 테스트가 포함되어 있습니다.
하지만 여기에는 두 가지 문제가 있습니다:
- 이 테스트들은 실행하는 데 너무 오래 걸립니다. 각 테스트는 약 2~4초가 소요되며 매번 결과를 기다려야 합니다. 그리 효율적이지 않습니다.
- 코드를 준비하고 실행하는 데 추가 시간이 걸리기 때문에 해결책이 실행되는 정확한 시간을 신뢰할 수 없습니다. 상수를 추가할 수도 있지만, 그 시간은 머신마다 다를 것입니다. 모의 서비스 지연 시간은 이 상수보다 높아야 차이를 볼 수 있습니다. 상수가 0.5초라면 지연 시간을 0.1초로 설정하는 것만으로는 충분하지 않습니다.
더 나은 방법은 동일한 코드를 여러 번 실행하면서 타이밍을 테스트하는 특별한 프레임워크를 사용하는 것이지만(전체 시간은 더욱 늘어납니다), 배우고 설정하기가 복잡합니다.
이러한 문제를 해결하고 제공된 테스트 지연 시간이 있는 해결책들이 예상대로 작동하는지(하나는 다른 하나보다 빠르게) 확인하려면 특별한 테스트 디스패처와 함께 가상(virtual) 시간을 사용하세요. 이 디스패처는 시작부터 경과된 가상 시간을 추적하고 실제 시간에는 즉시 모든 것을 실행합니다. 이 디스패처에서 코루틴을 실행하면 delay는 즉시 반환되고 가상 시간을 전진시킵니다.
이 메커니즘을 사용하는 테스트는 빠르게 실행되지만 여전히 가상 시간의 서로 다른 순간에 어떤 일이 일어나는지 확인할 수 있습니다. 총 실행 시간이 대폭 감소합니다:

가상 시간을 사용하려면 runBlocking 호출을 runTest로 교체하세요. runTest는 TestScope에 대한 확장 람다를 인자로 받습니다. 이 특별한 스코프 내부의 suspend 함수에서 delay를 호출하면 delay는 실제 시간을 지연시키는 대신 가상 시간을 증가시킵니다:
@Test
fun testDelayInSuspend() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
foo()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 6 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun foo() {
delay(1000) // 지연 없이 자동으로 전진
println("foo") // foo() 호출 시 즉시 실행
}TestScope의 currentTime 속성을 사용하여 현재 가상 시간을 확인할 수 있습니다.
이 예제에서 실제 실행 시간은 수 밀리초인 반면, 가상 시간은 1000밀리초인 지연 인자와 동일합니다.
자식 코루틴에서 "가상" delay 효과를 완전히 얻으려면, 모든 자식 코루틴을 TestDispatcher로 시작해야 합니다. 그렇지 않으면 작동하지 않습니다. 이 디스패처는 다른 디스패처를 제공하지 않는 한 다른 TestScope로부터 자동으로 상속됩니다:
@Test
fun testDelayInLaunch() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
bar()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 11 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun bar() = coroutineScope {
launch {
delay(1000) // 지연 없이 자동으로 전진
println("bar") // bar() 호출 시 즉시 실행
}
}위의 예제에서 launch가 Dispatchers.Default 컨텍스트로 호출되면 테스트는 실패합니다. 잡(job)이 아직 완료되지 않았다는 예외가 발생할 것입니다.
loadContributorsConcurrent() 함수가 Dispatchers.Default 디스패처를 사용하여 수정하지 않고 상속된 컨텍스트로 자식 코루틴을 시작하는 경우에만 이 방식으로 테스트할 수 있습니다.
디스패처와 같은 컨텍스트 요소를 함수를 _정의_할 때가 아니라 _호출_할 때 지정할 수 있으므로 더 유연하고 테스트하기가 쉬워집니다.
가상 시간을 지원하는 테스트 API는 실험적(Experimental)이며 향후 변경될 수 있습니다.
기본적으로 컴파일러는 실험적인 테스트 API를 사용하면 경고를 표시합니다. 이 경고를 억제하려면 테스트 함수나 테스트를 포함하는 전체 클래스에 @OptIn(ExperimentalCoroutinesApi::class) 주석을 추가하세요. 실험적인 API를 사용 중임을 컴파일러에 알리는 컴파일러 인자를 추가합니다:
compileTestKotlin {
kotlinOptions {
freeCompilerArgs += "-Xuse-experimental=kotlin.Experimental"
}
}이 튜토리얼에 해당하는 프로젝트에는 이미 Gradle 스크립트에 컴파일러 인자가 추가되어 있습니다.
과제 8
tests/tasks/에 있는 다음 테스트들이 실제 시간 대신 가상 시간을 사용하도록 리팩토링하세요:
- Request4SuspendKtTest.kt
- Request5ConcurrentKtTest.kt
- Request6ProgressKtTest.kt
- Request7ChannelsKtTest.kt
리팩토링 전후의 총 실행 시간을 비교해 보세요.
과제 8을 위한 팁
runBlocking호출을runTest로 바꾸고System.currentTimeMillis()를currentTime으로 바꿉니다:kotlin@Test fun test() = runTest { val startTime = currentTime // 작업 수행 val totalTime = currentTime - startTime // 결과 테스트 }정확한 가상 시간을 확인하는 단언문(assertions)의 주석을 해제합니다.
@UseExperimental(ExperimentalCoroutinesApi::class)를 추가하는 것을 잊지 마세요.
과제 8 솔루션
동시성(concurrent) 및 채널(channels) 사례에 대한 솔루션은 다음과 같습니다:
fun testConcurrent() = runTest {
val startTime = currentTime
val result = loadContributorsConcurrent(MockGithubService, testRequestData)
Assert.assertEquals("Wrong result for 'loadContributorsConcurrent'", expectedConcurrentResults.users, result)
val totalTime = currentTime - startTime
Assert.assertEquals(
"The calls run concurrently, so the total virtual time should be 2200 ms: " +
"1000 for repos request plus max(1000, 1200, 800) = 1200 for concurrent contributors requests)",
expectedConcurrentResults.timeFromStart, totalTime
)
}먼저 예상되는 가상 시간에 결과가 제공되는지 확인한 다음 결과 자체를 확인합니다:
fun testChannels() = runTest {
val startTime = currentTime
var index = 0
loadContributorsChannels(MockGithubService, testRequestData) { users, _ ->
val expected = concurrentProgressResults[index++]
val time = currentTime - startTime
Assert.assertEquals(
"Expected intermediate results after ${expected.timeFromStart} ms:",
expected.timeFromStart, time
)
Assert.assertEquals("Wrong intermediate results after $time:", expected.users, users)
}
}채널을 사용한 마지막 버전의 첫 번째 중간 결과는 progress 버전보다 일찍 사용 가능해지며, 가상 시간을 사용하는 테스트에서 그 차이를 확인할 수 있습니다.
나머지 "suspend" 및 "progress" 과제에 대한 테스트도 매우 유사합니다. 프로젝트의
solutions브랜치에서 찾을 수 있습니다.
다음 단계
- KotlinConf의 Asynchronous Programming with Kotlin 워크숍을 확인해 보세요.
- 가상 시간 및 실험적인 테스트 패키지 사용에 대해 더 자세히 알아보세요.