从文件获取数据
Kotlin Notebook 结合 Kotlin DataFrame 库,使您能够处理非结构化和结构化数据。这种组合提供了将非结构化数据(例如 TXT 文件中的数据)转换为结构化数据集的灵活性。
对于数据转换,您可以使用 .add()、.split()、.convert() 和 .parse() 等方法。此外,该工具集还支持从各种结构化文件格式中获取和操作数据,包括 CSV、JSON、XLS、Parquet 和 Apache Arrow。请参阅 DataFrame 文档查看所有支持的格式。
在本指南中,您可以通过多个示例学习如何获取、精炼和处理数据。
开始之前
Kotlin Notebook 依赖于 Kotlin Notebook 插件,该插件在 IntelliJ IDEA 中默认内置并启用。
如果 Kotlin Notebook 功能不可用,请确保已启用该插件。有关更多信息,请参阅设置环境。
要按照本教程操作:
创建一个新的 Kotlin Notebook。
导入 Kotlin DataFrame:
kotlin%use dataframe
在运行任何其他代码单元之前,请确保先运行包含
%use dataframe行的代码单元,以确保 DataFrame 库及其 API 在笔记本中可用。
获取数据
要在 Kotlin Notebook 中从文件获取数据,请使用 DataFrame.read() 函数:
val movies = DataFrame.read("movies.csv")DataFrame.read() 函数会根据文件扩展名和内容自动检测输入格式。
您还可以传递其他实参来控制 DataFrame 库读取输入数据的方式。例如,以下代码为 CSV 文件指定了自定义分隔符 (;):
val movies = DataFrame.read("movies.csv", delimiter = ';')有关其他文件格式的全面概览以及各种读取函数的详细信息,请参阅 Kotlin DataFrame 库文档。
显示数据
一旦在笔记本中拥有数据,您就可以将其显示出来。最简单的方法是将数据存储在变量中,然后将其返回:
val jsonDf = DataFrame.read("jsonFile.json")
jsonDf此代码将文件中的数据显示为交互式表格:
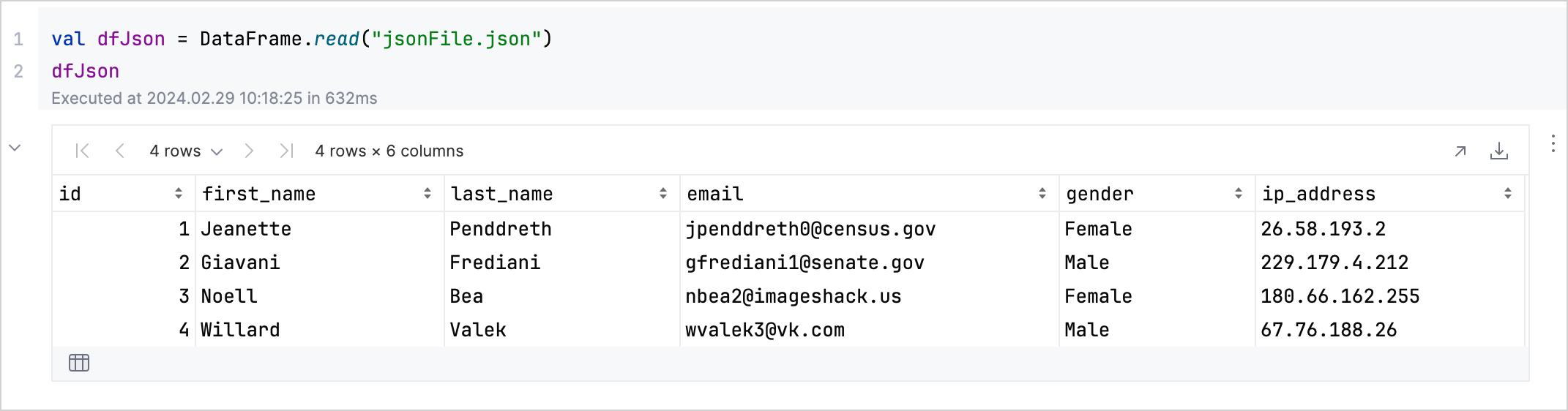
您可以使用此视图来检查值、查看列名,并轻松了解数据集的状态。
检查数据结构
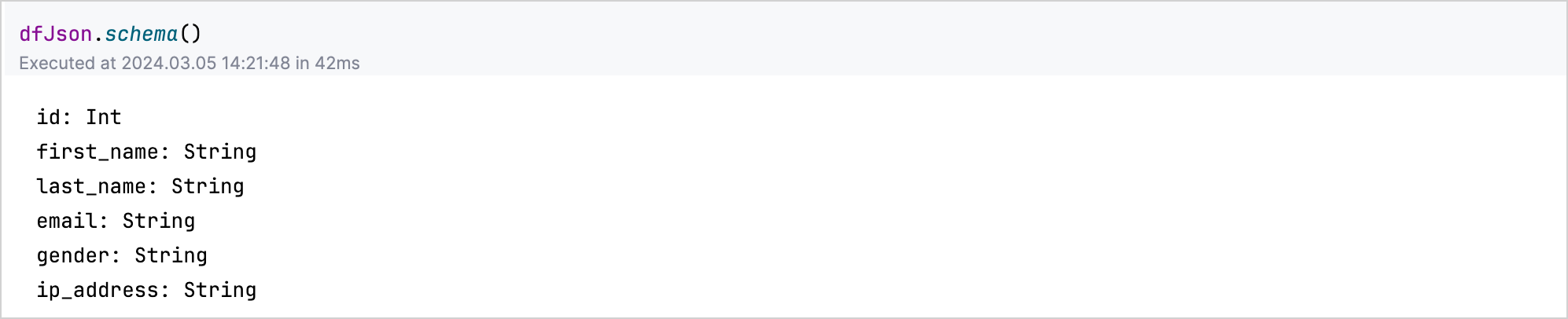
要深入了解数据的结构或架构,请对 DataFrame 变量调用 .schema() 函数。
例如,运行 jsonDf.schema() 会列出 JSON 数据集中每一列的类型:
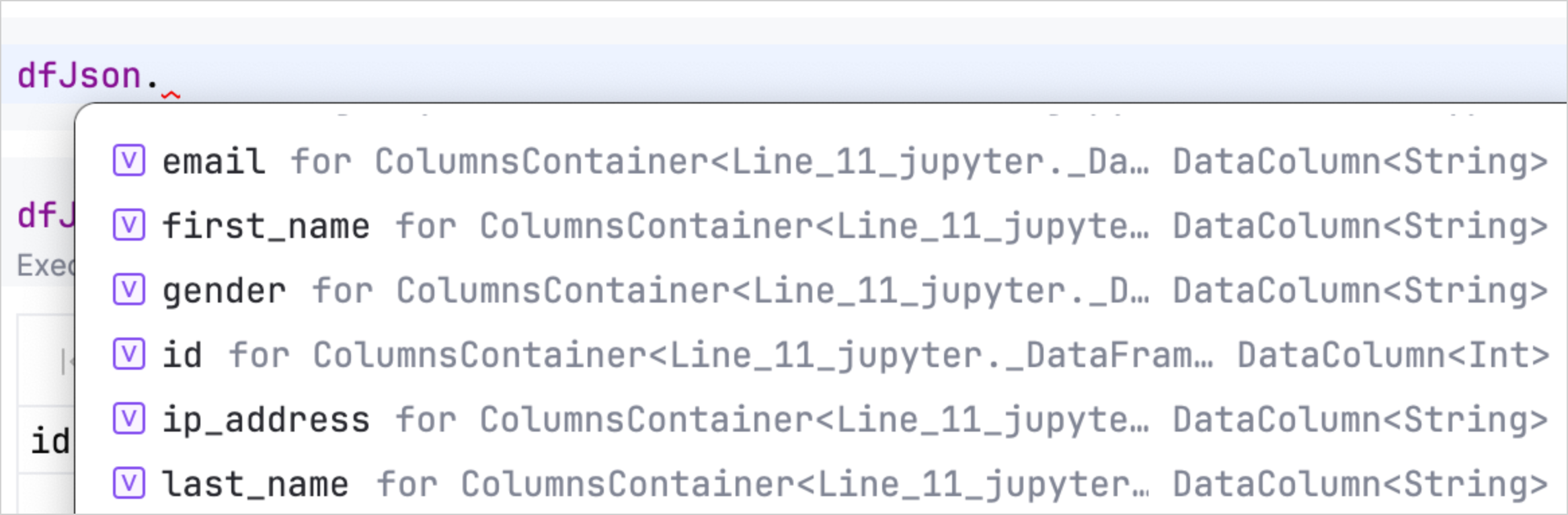
通过 Kotlin Notebook,您还可以使用自动补全功能。它可以让您快速访问和操作 DataFrame 的属性。加载数据后,只需输入 DataFrame 变量名后跟一个点 (.),即可查看可用列及其类型的列表。
精炼数据
Kotlin DataFrame 提供了用于精炼数据集的各种操作。例如,分组、筛选、更新或添加新列。这些函数对于数据分析至关重要,让您可以有效地组织、清洗和转换数据。
例如,让我们看看 movies.csv 数据集。它在同一个单元格中存储了电影标题和发行年份。目标是精炼此数据集以便于分析:
加载数据
使用
.read()函数将文件加载到DataFrame中:kotlinval movies = DataFrame.read("movies.csv")添加列
要从
title列中提取发行年份,请添加一个新的year列:kotlinval moviesWithYear = movies .add("year") { "\\d{4}".toRegex() .findAll(title) .lastOrNull() ?.value ?.toInt() ?: -1 } moviesWithYear更新值
要从电影标题中移除发行年份,请更新
title列:kotlinval moviesTitle = moviesWithYear .update("title") { "\\s*\\(\\d{4}\\)\\s*$".toRegex().replace(title, "") } moviesTitle这段代码将电影标题保留在一列中,并将发行年份移动到另一列。
筛选行
要专注于特定数据,请使用
.filter()函数。例如,要仅保留 1986 年以后发行的电影,请运行:kotlinval newMovies = moviesTitle.filter { year >= 1996 } newMovies移除列
要移除不需要的列,请使用
.remove()函数:kotlinval refinedMovies = newMovies.remove { movieID } refinedMovies
作为对比,以下是精炼前的数据集:
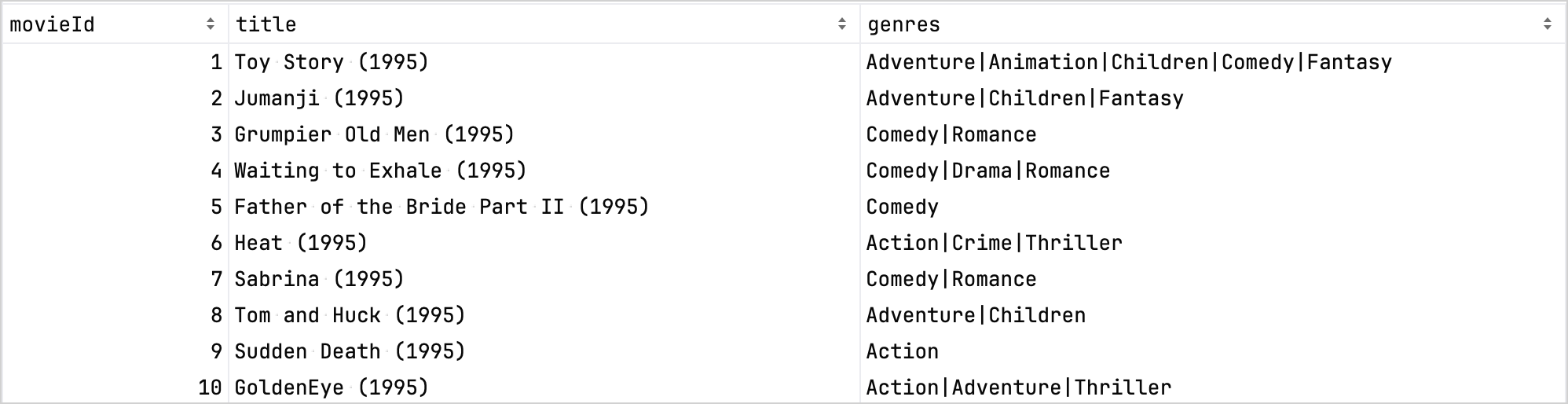
精炼后的数据集:
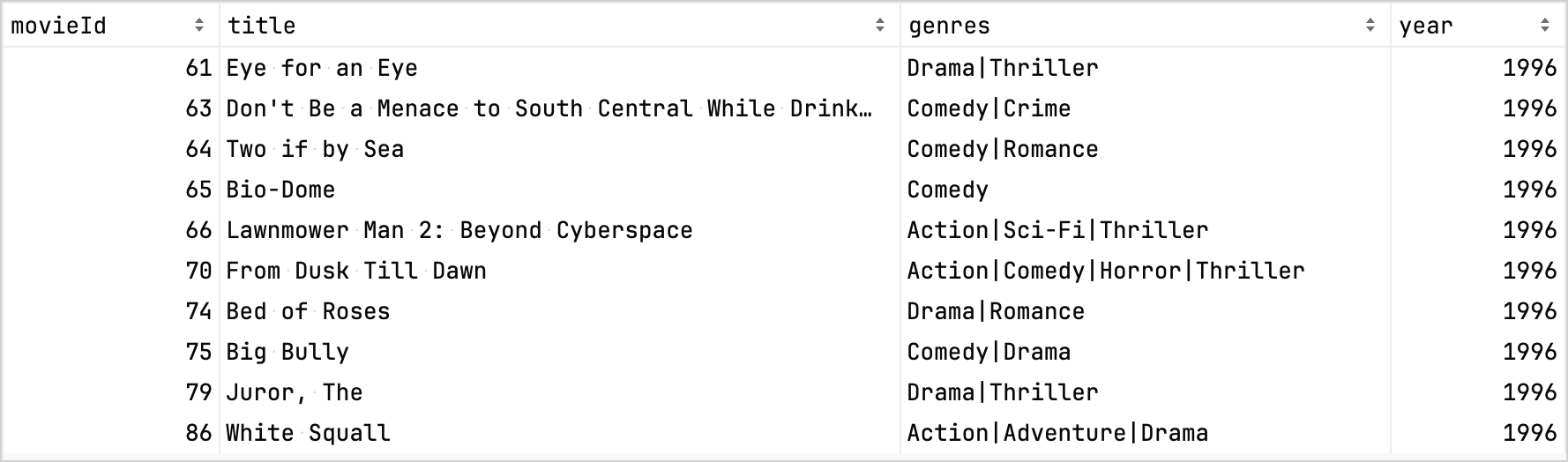
有关更多用例和详细示例,请参阅 Kotlin Dataframe 示例。
导出数据
在 Kotlin Notebook 中精炼数据后,您可以轻松导出处理后的数据。
您可以为此使用各种 .write() 函数。它支持保存为多种格式,包括 CSV、JSON、XLS、XLSX、Apache Arrow,甚至是 HTML 表格。请参阅 DataFrame 文档查看所有支持的格式。这对于分享您的发现、创建报告或使数据可用于进一步分析特别有用。
例如,我们将结果保存为:
使用
.writeJson()函数保存为 JSON 文件:kotlinrefinedMovies.writeJson("movies.json")使用
.writeCsv()函数保存为 CSV 文件:kotlinrefinedMovies.writeCsv("movies.csv")使用
.writeArrowIPC()和.writeArrowFeather()函数保存为 Apache Arrow 文件:kotlinrefinedMovies.writeArrowIPC("movies.arrow") refinedMovies.writeArrowFeather("movies.feather")
您还可以使用 .toStandaloneHTML() 函数在浏览器中打开独立的 HTML 表格:
refinedMoviesDf
.toStandaloneHTML(DisplayConfiguration(rowsLimit = null))
.openInBrowser()下一步
- 探索使用 Kandy 库进行数据可视化
- 在在 Kotlin Notebook 中使用 Kandy 进行数据可视化中查找有关数据可视化的更多信息
- 有关 Kotlin 中可用于数据科学和分析的工具和资源的广泛概览,请参阅用于数据分析的 Kotlin 和 Java 库